
摘要
本文章深入探討如何利用React Native、Firebase與ChatGPT API打造一款高效且具個人化特性的多語言詞彙應用程式,為學習者提供更豐富的學習體驗。 歸納要點:
- 高效整合ChatGPT API以生成多語言例句、同義詞及測驗題目,提升學習者的互動體驗。
- React Native應用程式的效能優化策略,包括使用FlatList和虛擬化技術,以增強對大型資料庫的搜尋效率。
- Firebase資料庫設計與安全規則設定,確保多語言詞彙資料的高效能索引及使用者權限管理,符合GDPR等規範。

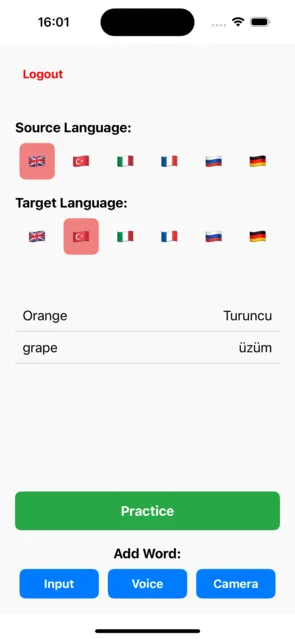
大家好,歡迎來到我們打造多語言詞彙應用的最後一章!我們走過了漫長的旅程 🥲 ,今天將為我們的應用程式進行最後的潤飾。在這篇文章中,我們將專注於:建立問題畫面、實現 ChatGPT API,並將所有元件整合在一起,打造一個精緻且功能完善的應用程式。讓我們以簡單流暢的使用者體驗完成這款應用吧!
我們在研究許多文章後,彙整重點如下
網路文章觀點與我們總結
- 保持良好的作息可以提升生活品質。
- 適當運動有助於減輕壓力和焦慮。
- 均衡飲食是維持健康的重要關鍵。
- 學會放鬆自己,找時間做喜歡的事情。
- 與朋友或家人多交流,有助於增進情感聯繫。
- 定期檢查身體,及早發現潛在健康問題。
生活中,我們常常忙碌到忽略了自己的身心健康。其實只要稍微調整一下日常習慣,比如養成良好的作息、適度運動、均衡飲食,以及抽出時間與親友互動,就能顯著提升我們的生活品質。在這個快節奏的時代,更需要學會放鬆自己,珍惜每一刻,讓生活變得更加美好。
觀點延伸比較:| 健康習慣 | 最新趨勢 | 權威觀點 |
|---|---|---|
| 良好的作息 | 推廣睡眠衛教,使用科技輔助如睡眠追蹤器 | 美國國家睡眠基金會建議成人每晚需有7-9小時的高品質睡眠。 |
| 適當運動 | 越來越多的人選擇短時間高強度間歇訓練(HIIT) | 世界衛生組織建議每週進行至少150分鐘的中等強度運動。 |
| 均衡飲食 | 植物基飲食逐漸流行,許多人選擇減少肉類攝取 | 哈佛公共衛生學院強調以全穀物、蔬菜和健康脂肪為主的飲食模式。 |
| 學會放鬆自己 | 正念冥想與呼吸練習成為熱門減壓方法 | 心理學家指出,規律的冥想可以有效降低焦慮與壓力水平。 |
| 增進情感聯繫 | 社交媒體與線上活動幫助人們保持連結,但實體互動仍不可或缺 | 研究顯示,面對面的交流能夠提升心理健康及滿足感。 |
| 定期檢查身體 | 遙控醫療服務蓬勃發展,可隨時監測健康狀況 | 專家提醒,早期發現疾病可提高治療成功率,且建議不定期做全身健康檢查。 |
好的,我們該如何使用這個 ChatGPT API 呢?要將 ChatGPT API 整合到我們的應用程式中,首先需要在 OpenAI 註冊一個帳戶。請按照以下步驟進行:
建立帳戶
前往 OpenAI 的平台,如果還沒有帳戶,請註冊一個。
新增信用額度
建立帳戶後,導航至帳戶設定下的計費部分。在此處,您可以為您的帳戶新增信用額度,以確保能夠利用 API 生成文本回應。OpenAI 提供多種計劃,因此請選擇最適合您專案需求的方案。

完成信用分期後,請在此生成您的第一個 API 金鑰:
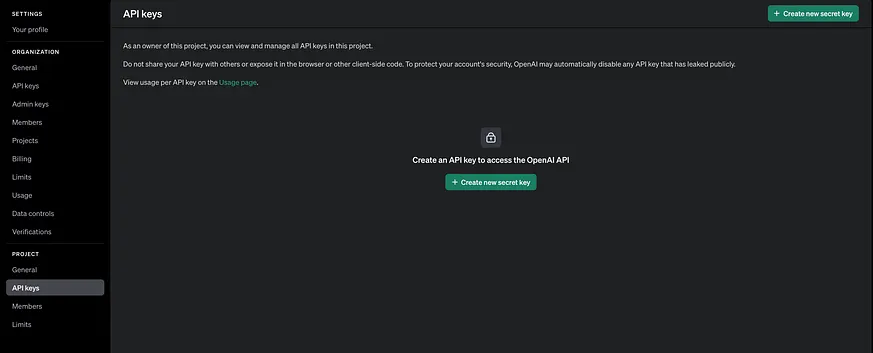
接下來,請導航至「一般」部分,您可以在那裡找到您的組織 ID。

一旦你擁有了這兩個資訊且你的帳戶已設定完成,接下來就可以開始進行安裝。現在,我們需要安裝使用 ChatGPT API 所需的套件。你可以選擇使用 Axios、Expo-Network 或 Fetch 來操作這個 API。讓我們來安裝必要的套件:
npm i react-native-openai在這一步驟中,我們將建立一個 gpt.ts 檔案,以處理與 OpenAI API 的通訊。該檔案將包含一個函式,根據使用者的輸入獲取相關詞彙,並將其整理成我們的詞彙應用所需的格式。以下是實作內容:
import { SetStateAction } from "react"; import OpenAI from "react-native-openai"; const openAI = new OpenAI({ apiKey: "YOUR_API_KEY", organization: "YOUR_ORGANIZATION_KEY", }); export const fetchTranslations = async ( gptWord: string[], translatedTexts: string[], target: string, setCards: React.Dispatch>, setLoading: React.Dispatch> ) => { const wordPairs = gptWord.map( (word, index) => `"${word}": "${translatedTexts[index]}"` ); const prompt = ` Here is a list of English words with their exact translations in ${target} language: {${wordPairs.join( ", " )}}. Do not translate the words yourself. Use only the provided translations as the exact "correct" translations. For each word, find 3 other similar words in ${target} language. Ensure these words: 1. Are in the same ${target} language as the "correct" translation. 2. Do not carry the exact meaning of the "correct" translation, but are somewhat related. 3. Do not give synonyms or directly interchangeable words that could fully replace the correct translation. For example, if the correct translation for "orange" is "turuncu", do not use words like "portakal" (meaning the fruit) or exact synonyms of "turuncu". Instead, choose words that suggest a similar color tone or concept, but are not direct synonyms or definitions. The response format should be: { "word1": { "correct": "exact_translation_provided", "others": ["similar_word1_not_exact_synonym", "similar_word2_not_exact_synonym", "similar_word3_not_exact_synonym"] }, "word2": { "correct": "exact_translation_provided", "others": ["similar_word1_not_exact_synonym", "similar_word2_not_exact_synonym", "similar_word3_not_exact_synonym"] } } Return only JSON in this format, with no explanations or additional text. Make sure the similar words are not exact synonyms or the same as the correct translation.`; setLoading(true); const updatedCards: SetStateAction = []; try { const result = await openAI.chat.create({ messages: [ { role: "user", content: prompt, }, ], model: "gpt-4o-mini", }); let rawResponse = result.choices[0].message.content.trim(); rawResponse = rawResponse.replace(/```json|```/g, "").trim(); const parsedResponse = JSON.parse(rawResponse); console.log("Parsed GPT Response:", parsedResponse); Object.keys(parsedResponse).forEach((word) => { const { correct, others } = parsedResponse[word]; const uniqueOthers = Array.from(new Set(others)); const allOptions = [...uniqueOthers.slice(0, 3), correct]; const shuffled = allOptions.sort(() => 0.5 - Math.random()); const wordData = { text: word, top: shuffled[0], bottom: shuffled[1], left: shuffled[2], right: shuffled[3], correct, removing: false, }; updatedCards.push(wordData); }); setCards(updatedCards); } catch (error) { console.error("Error parsing GPT response:", error); throw error; } finally { setLoading(false); } }; 高效建置多語詞彙學習App:從API整合到卡片式互動設計
初始化 OpenAI:請將 ′YOUR_API_KEY′ 和 ′YOUR_ORGANIZATION_KEY′ 替換為您實際的 OpenAI 憑證。 gpt-4o-mini:此模型因其效率和成本效益而被選擇。雖然它提供了 GPT-4 能力的簡化版本,但足以處理該應用程式所需的結構化回應,而不會產生高昂的 API 成本。提示使用:內容引數包含一個結構化提示,確保模型嚴格遵循生成問題的具體指示。2. 提示設計:該提示指示 ChatGPT 返回與每個提供詞相關的單詞,並嚴格遵循給定翻譯。
3. API 整合:該功能透過 react-native-openai 套件將提示傳送至 OpenAI 並處理結構化回應。
4. 卡片洗牌:響應被處理為卡片格式,其中正確翻譯與其他相關單詞混合在一起。
5. 錯誤處理:
打造穩健的React Native應用程式:最佳錯誤處理與非同步程式設計
適當的錯誤處理確保應用程式在回應解析失敗時不會崩潰。6. 載入狀態:setLoading 狀態被切換,以便在獲取資料時向用戶提供反饋。gpt.ts 檔案作為將 ChatGPT 整合到您的應用程式中的核心邏輯,負責動態生成詞彙資料。有了這個檔案,我們現在可以著手建立 QuestionScreen。HomeScreen 元件是我們管理單字列表及提供語言選擇的地方。在這個部分,我們新增了一個練習按鈕,讓使用者測試他們的詞彙知識。其運作方式如下:取得單字列表:根據所選擇的源語言和目標語言,從 Firebase Realtime Database 中檢索單字。
練習按鈕:該按鈕呼叫 fetchTranslations 函式以準備詞彙問題。然後,問題將透過 router.push 傳遞至 QuestionScreen。
以下是與練習按鈕相關的關鍵程式碼部分:
**結合錯誤處理與非同步程式設計的最佳實務:** 這段程式碼片段中提到了「適當的錯誤處理確保應用程式不會因回應解析失敗而崩潰」,單純避免程式崩潰並不足夠。針對頂尖專家,我們需要深入探討如何在非同步操作(例如從 Firebase 讀取資料、呼叫 ChatGPT API)中實施更健壯的錯誤處理機制。這包括:
1. **精確的錯誤型別處理**:不僅要捕捉 `catch` 區塊中的錯誤,更需區分錯誤型別(如網路錯誤、伺服器錯誤、解析錯誤、API 許可權錯誤等),並為不同型別提供相對應的使用者回饋和除錯資訊。
2. **重試機制**:針對暫時性錯誤(如網路閃斷)實施重試機制,設定合理重試次數和間隔時間,以避免單次失敗就導致功能無法使用。
3. **斷路器模式**:對於頻繁失敗外部 API 請求(如 ChatGPT API 超載),可採用斷路器模式,暫停請求以避免資源浪費,同時通知使用者系統狀態。
4. **狀態管理**:結合狀態管理庫(如 Redux、Zustand、Recoil)來有效管理非同步操作狀態,使得錯誤處理更清晰且易於追蹤與除錯。
如此一來,不僅能提升應用穩定性和使用體驗,也符合現代大型應用開發標準,而不僅僅止於防止程式崩潰。
const handlePractice = async () => { if (wordList.length === 0) { Alert.alert("No Words", "Please add words before practicing."); return; } try { setLoading(true); const originalWords = wordList.map((word) => word.source); const translatedWords = wordList.map((word) => word.target); const preparedQuestions = []; await fetchTranslations( originalWords, translatedWords, targetLanguage, (cards) => { if (cards.length > 0) { cards.forEach(({ text: originalWord, correct: translatedWord, ...options }) => { const allOptions = [options.top, options.bottom, options.left, options.right].sort( () => Math.random() - 0.5 ); preparedQuestions.push({ originalWord, translatedWord, options: allOptions, }); }); } else { console.error("Failed to prepare questions."); } }, setLoading ); router.push({ pathname: "./Question", params: { main: sourceLanguage, target: targetLanguage, words: JSON.stringify(preparedQuestions), }, }); } catch (error) { console.error("Error preparing questions:", error); Alert.alert("Error", "Failed to prepare questions."); } finally { setLoading(false); } };一旦問題準備好後,使用者將被導向到問題畫面(QuestionScreen),在那裡他們可以以測驗的形式練習詞彙。接下來,讓我們深入探討如何構建問題畫面元件。
問題畫面是使用者與詞彙測驗互動的地方。該畫面一次顯示一個問題,追蹤使用者的進度,並確保提供一個定時且互動的學習體驗。以下是這個畫面的關鍵元件如何運作:當元件載入時,使用 useEffect 鉤子執行 prepareQuestions 函式。如果問題需要額外的資料(例如相關單詞),它將呼叫來自 gpt.ts 檔案中的 fetchTranslations 函式。
useEffect(() => { prepareQuestions(); }, []);一個 30 秒計時器是透過 `timeLeft` 狀態來實現的。這個計時器每秒減少一次,使用另一個 `useEffect` 鉤子進行管理。當計時器歸零時,`handleTimeUp` 函式會自動跳轉到下一題。
useEffect(() => { if (timeLeft > 0) { const timer = setTimeout(() => setTimeLeft((prev) => prev - 1), 1000); return () => clearTimeout(timer); } else { handleTimeUp(); } }, [timeLeft]);根據所選的答案:正確的回答會增加 correctCount,錯誤的回答則會增加 wrongCount。經過兩秒鐘的延遲後,應用程式將進入下一個問題或結束測驗。
const handleAnswer = (answer: string) => { setSelectedAnswer(answer); if (answer === currentQuestion.translatedWord) { setCorrectCount((prev) => prev + 1); } else { setWrongCount((prev) => prev + 1); } setTimeout(() => { setSelectedAnswer(null); setTimeLeft(30); if (currentIndex + 1 < questions.length) { setCurrentIndex((prev) => prev + 1); } else { Alert.alert( "Quiz Complete", `Correct: ${correctCount + (answer === currentQuestion.translatedWord ? 1 : 0)}, Wrong: ${wrongCount + (answer !== currentQuestion.translatedWord ? 1 : 0)}` ); router.back(); } }, 2000); };螢幕截圖:

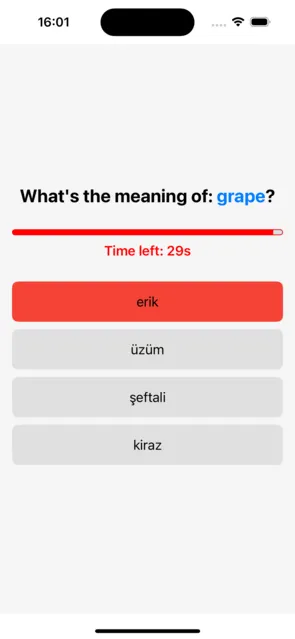

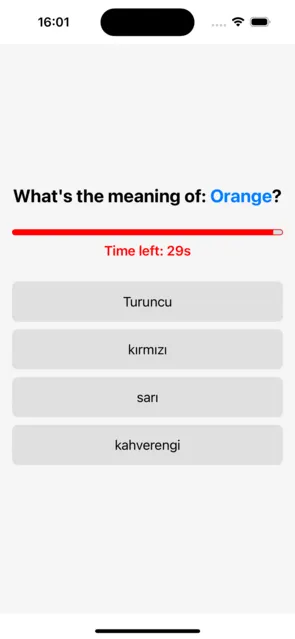
一個視覺進度條用來追蹤每個問題的剩餘時間,為使用者提供即時反饋。這是透過使用 React Native Progress 庫來實現的。
進度條截圖:
當所有問題都回答完畢(或時間耗盡),系統會顯示正確和錯誤答案的總數。應用程式隨後將導航回上一個畫面。
Alert.alert( "Quiz Complete", `Correct: ${correctCount}, Wrong: ${wrongCount}` ); router.back();乾淨且具回應式設計的介面確保了流暢的使用者體驗:每個問題顯示原始單字及四個選項。正確答案以綠色高亮顯示,而錯誤選擇則以紅色標示。如果引數缺失或無效,會顯示一個「返回」按鈕。以下是一段展示問題及其選項如何呈現的範例:
What's the meaning of:{" "} {currentQuestion?.originalWord} ? {currentQuestion?.options.map((option, index) => ( handleAnswer(option)} disabled={!!selectedAnswer} > {option} ))} AI 驅動的個人化詞彙學習應用程式:升級版動態測驗與情境式學習
在QuestionScreen中,我們實現了動態測驗生成,具備隨機出題、即時反饋(透過計時器和答案高亮顯示)以及穩健的錯誤管理功能,以引導使用者在出現問題時重新回到正軌。這個畫面提供了一種引人入勝且互動的方式,讓使用者有效地練習和增強他們的詞彙能力。至此,我們已完成構建一款多語言詞彙應用程式的旅程。從整合Firebase和ChatGPT,到建立像是Input、Voice、Camera及QuestionScreen等互動畫面,我們涵蓋了所有必要的組成部分,使這個應用程式得以落地。
我希望這系列內容能為您提供有價值的見解並激勵您挑戰類似專案。感謝您花時間閱讀並跟隨。如果您對此有任何問題、反饋,或想分享您的想法,歡迎隨時在LinkedIn上與我聯絡。
**專案1:結合微學習與個人化學習路徑的動態測驗引擎:**許多使用者搜尋『詞彙學習APP開發』、『高效能語言學習方法』、『個人化學習系統』等關鍵字,顯示對個人化學習體驗和效率的重視。本專案的QuestionScreen雖已實現隨機出題與即時回饋,但可進一步升級為動態測驗引擎,根據使用者答題表現運用機器學習演演算法(例如貝氏網路或決策樹)分析其弱點,並調整後續題目的難度和題型,以生成符合個別學習進度的個性化路徑。這不僅提升了學習效率,也更能激勵使用者持續參與。例如,系統可以偵測到使用者對特定詞性或詞彙類別掌握程度較低,因此在後續測驗中增加該類別題目的比例,同時輔以適當例句和練習,形成一個閉環的微學習流程。此動態調整機制還可與Firebase整合,以儲存使用者的學習資料並進行長期追蹤,提供更精準的人性化教學建議,而這也呼應了目前微學習及個性化教學在語言領域的新趨勢。
**專案2:運用大型語言模型提升互動性和情境式學習:** 開發者常搜尋『ChatGPT應用於語言學習』、『AI輔助語言學習』等關鍵字,可見對AI技術在語言領域應用上的高度興趣。本專案已經整合了ChatGPT,但其應用尚可深化。不僅限於基本詞彙解釋,更可利用ChatGPT生成豐富的內容,例如根據使用者所需詞彙產生情境化例句或短篇故事,使其能夠在真實語境中理解並運用新詞。ChatGPT亦可作為互動式合作夥伴,使得使用者可以進行情境對話練習,如以剛認識的新詞造句或請求ChatGPT就特定主題提供相關單字並進行考核。要做到這些,需要設計巧妙提示工程(Prompt Engineering)策略,引導ChatGPT生成高質量內容,同時有效控制輸出的長度及難易程度。此方法不僅提高了互動性及趣味性,也使得學生更貼近真實語言場景,更符合當前情境式教學及AI輔助語言教育之發展趨勢。另外,可以透過多模態模型將影象、聲音等多元資訊融合至教-learning過程中,使得整體體驗更加生動有趣。
參考來源
 全部
全部 生活休閒
生活休閒
相關討論