
摘要
本篇文章將引領讀者了解如何運用 React Native、Firebase 與 Chat GPT 打造一款高效且具多語言支持的詞彙應用程式,並揭示其背後的進階技術應用。 歸納要點:
- 深入探討 Firebase Realtime Database 的安全設定與離線優先策略,提升使用者體驗並實現資料版本控制及衝突解決機制。
- 利用 TypeScript 和 Flag.ts 建立強健的多語言系統,整合各種翻譯平台以確保翻譯的一致性和準確性。
- 研究 WebAssembly 技術在語音學習中的應用,優化大型模型至離線環境,同時結合影像處理技術提升 OCR 的準確性。

大家好!今天,我們將深入探討我們的多語言詞彙應用程式的開發。在這一篇中,我們將涵蓋幾個令人興奮的主題,包括:如何有效利用 Firebase Realtime Database、建立輸入、語音和相機介面、整合高階功能如語音轉文字和光學字元識別(OCR),以及最重要的,即使用 translate-google-api 庫動態翻譯單詞。讓我們開始吧,探索這些元素如何結合起來,創造出無縫且友好的使用體驗!
我們在研究許多文章後,彙整重點如下
網路文章觀點與我們總結
- 許多人在生活中面臨壓力與挑戰,這是常態。
- 保持正向思維有助於減輕焦慮和提升情緒。
- 建立良好的社交網絡可以提供情感支持。
- 定期運動被證實能顯著改善心理健康。
- 學習放鬆技巧,如冥想或深呼吸,有助於自我調適。
- 設定小目標並逐步達成,可以增加自信心和成就感。
生活中每個人都會遭遇各種壓力與挑戰,這些都是我們共同的經歷。在應對困難時,保持正向的心態、培養良好的社交關係以及進行規律的運動,都能幫助我們緩解焦慮。此外,掌握一些放鬆技巧也非常重要。而設定合理的小目標,更能讓我們在追求夢想的過程中獲得更多成就感和快樂。因此,我們不妨試著將這些方法融入日常生活,以提升自己的心理健康。
觀點延伸比較:| 策略 | 具體做法 | 最新趨勢 | 權威觀點 |
|---|---|---|---|
| 正向思維 | 每日寫下三件感恩的事 | 感恩日記越來越受歡迎,提升幸福感 | 哈佛大學研究顯示,感恩能改善心理健康 |
| 社交網絡建立 | 參加社區活動或興趣班 | 線上社交平台如 Meetup 的使用增加,促進實體聚會機會 | 心理學家建議強化支持系統以減輕壓力 |
| 定期運動 | 每週至少150分鐘有氧運動,如慢跑、游泳等 | 健身應用程式和虛擬教練的普及,提高人們運動的便利性與趣味性 | 世界衛生組織提倡定期運動作為良好心理健康的重要因素 |
| 放鬆技巧學習 | 參加冥想課程或使用冥想應用程式,如 Headspace 或 Calm | 數位工具使得冥想更容易被接受和實踐,尤其在年輕族群中流行 | 美國心理協會指出,冥想有助於降低焦慮和憂鬱症狀 |
| 設定小目標 | 制定 SMART 原則(具體、可衡量、可達成、相關性、時限)的小目標 | 個人發展計劃愈來愈受到重視,幫助人們保持專注與動力 | 成功人士常強調逐步達成目標的重要性,以增強自信心 |
在我們上一次的會議中,我們已經在應用程式中設定了 Firebase。現在,是時候捲起袖子,深入探討 Firebase Realtime Database 了。我們該如何連線它?又如何使其成為我們應用資料儲存的支柱?讓我們來逐步解析。第一步是在 Firebase 控制檯中啟用 Firebase Realtime Database:登入 Firebase 控制檯。選擇您的專案(如果還沒有專案,需要先建立一個)。導航至 Realtime Database 部分。點選「Create Database」,並選擇適合您資料的位置。
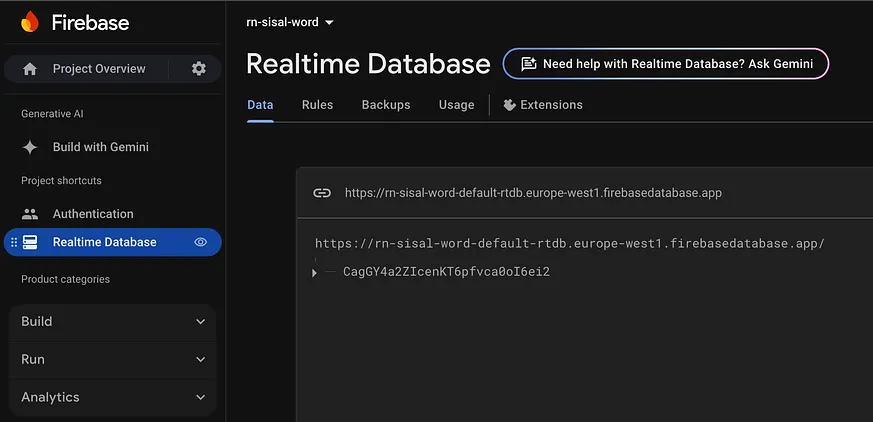
💡 提示:在設定過程中,系統會提示您選擇資料庫的安全規則。出於開發目的,您可以暫時使用以下規則允許公開訪問:
{ "rules": { ".read": true, ".write": true } }啟用 Firebase 資料庫後,下一步是透過將 databaseURL 新增到您的 Firebase 設定檔來配置它。具體操作如下:在您的專案中找到 firebase.ts 檔案(如果不存在則建立一個),並配置您的 Firebase 應用程式:
import { initializeApp } from 'firebase/app'; const firebaseConfig = { apiKey: 'AIzaSyABV9ZhadUctQy3R_d3P6TVG1W8-cNyWcY', authDomain: 'rn-sisal-word.firebaseapp.com', databaseURL: 'https://rn-sisal-word-default-rtdb.europe-west1.firebasedatabase.app/', projectId: 'rn-sisal-word', storageBucket: 'rn-sisal-word.firebasestorage.app', messagingSenderId: '851905218011', appId: '1:851905218011:web:e43114d7500dd7345fd3fe', measurementId: 'G-measurement-id', }; const app = initializeApp(firebaseConfig);Firebase Realtime Database:安全設定、離線功能與最佳實踐
2. databaseURL 的重要性databaseURL 對於使您的應用程式能夠連線到 Firebase Realtime Database 至關重要。若沒有它,您的應用程式將無法知道該向何處傳送或檢索資料。
3. 整合檢查點
在這個階段,您的 Firebase 應用程式已經配置完成並準備與資料庫互動。稍後,在我們建立輸入頁面時,將驗證這一整合。現在,我們已經整合了 Firebase 並設定好資料庫,是時候建立和完善主頁及輸入頁面了。我們來探討它們的功能以及如何協同工作,以提供無縫的使用者體驗。
輸入頁面是使用者可以快速透過鍵盤新增不熟悉單字的地方。這些單字隨即會被翻譯並儲存在 Firebase Realtime Database 中。透過即時新增功能,此頁面確保使用者不會錯失擴充詞彙的機會。
**Firebase Realtime Database URL 的安全考量與最佳實踐:** 雖然此段落著重於 databaseURL 的重要性,但卻未對安全性進行深入討論,這對於專家而言至關重要。在正確設定 databaseURL 的同時,更需強調透過 Firebase 安全規則精細控制資料存取許可權。例如,可以針對不同使用者角色(如管理員與一般使用者)設定不同的讀寫許可權,以避免未經授權的存取。應避免直接在應用程式碼中硬編碼 databaseURL,而是透過環境變數或專門設定檔來管理,以降低安全風險。同時,我們也要強調實施最小許可權原則,即僅授予應用程式必要的資料存取許可權。最新趨勢顯示,採用 Firebase Admin SDK 來管理安全規則和資料比直接從客戶端操作更具安全性。引入 Firebase Authentication 以整合身份驗證機制,也可確保只有經驗證的使用者才能訪問資料庫。
**離線功能與資料同步策略:** 雖然文章提到 Firebase Realtime Database 即時資料同步特性,但未涉及其離線功能。在開發高可用性的應用程式中,尤其是行動裝置上,離線功能尤為關鍵。一流專家會致力於有效利用 Firebase Realtime Database 的離線能力,使得即使在無網路連線下也能持續運作並儲存使用者輸入的資訊。這需要深入研究例如 `onDisconnect()` 方法如何在斷線狀態下執行特定操作,以及恢復網路連線後如何進行資料同步問題解決的一系列方案。其中一個關鍵議題便是資料衝突解決策略:當多裝置同時修改相同資料時,要保障資料的一致性和完整性。在典型查詢意圖「Firebase Realtime Database 離線功能如何實現」中,可以提供詳細程式碼範例,例如如何利用 `onDisconnect()` 和事件監聽器來處理斷網事件及恢復後同步問題。需要介紹各種不同的資料同步策略,如單向及雙向同步,以及其各自優缺點,以幫助專家根據需求選擇最佳方案。目前有一大趨勢是在結合其他Firebase服務(如 Cloud Functions)之下進行離線資料的同步和衝突解決,以提升系統穩定性及效能。
在我們建立首頁之前,我們需要建立一個配置檔案(Flag.ts),以管理支援的語言及其後設資料。這個檔案將提供以下內容:
- 標誌:用作語言選擇的圖示。
- 語言:顯示各種語言的名稱。
- 語音識別地區設定:用於語音轉文字功能。
- 語言家族:用於光學字元識別(OCR)整合。
以下是 Flag.ts 的程式碼:
export const Flags = { en: { flag: "🇬🇧 ", language: "English", speechRecognitionLocale: "en-US", family: "Latin", }, tr: { flag: "🇹🇷 ", language: "Turkish", speechRecognitionLocale: "tr-TR", family: "Latin", }, it: { flag: "🇮🇹 ", language: "Italian", speechRecognitionLocale: "it-IT", family: "Latin", }, fr: { flag: "🇫🇷 ", language: "French", speechRecognitionLocale: "fr-FR", family: "Latin", }, ru: { flag: "🇷🇺 ", language: "Russian", speechRecognitionLocale: "ru-RU", family: "Cyrillic", }, de: { flag: "🇩🇪 ", language: "German", speechRecognitionLocale: "de-DE", family: "Latin", } }為何要包含這些選項? 標誌:在首頁顯示直觀且視覺吸引的圖示。 語言:幫助使用者透過名稱識別語言。 語音辨識區域:使每種語言的精確語音輸入處理成為可能。 語言家族:支援光學字元識別(OCR)功能,這可能因不同書寫系統而異(例如,拉丁字母與西里爾字母)。 錯誤處理與載入狀態 平穩的使用者體驗至關重要。為了應對慢速網路響應或資料獲取過程中的錯誤,我們實現了一個載入狀態:
const [loading, setLoading] = useState(false); const fetchWordList = () => { setLoading(true); const auth = getAuth(); const currentUser = auth.currentUser; if (!currentUser) { Alert.alert("User not logged in", "Please log in to view your words."); setLoading(false); return; } const userId = currentUser.uid; const database = getDatabase(); const tablePath = `${userId}/words/${sourceLanguage}-${targetLanguage}`; const wordsRef = ref(database, tablePath); onValue(wordsRef, (snapshot) => { if (snapshot.exists()) { const words = snapshot.val(); const formattedWordList = Object.keys(words).map((key) => ({ id: key, source: words[key].original, target: words[key].translated, })); setWordList(formattedWordList); } else { setWordList([]); } setLoading(false); }); };這確保了使用者能夠了解應用程式的狀態,並改善整體的反應速度。2. 語言選擇 首頁使用國旗配置來呈現語言選項。使用者可以動態地選擇源語言和目標語言:
Source Language: {Object.keys(Flags).map((langCode) => ( setSourceLanguage(langCode)} style={[ styles.languageOption, sourceLanguage === langCode && styles.selectedLanguage, ]} > {Flags[langCode].flag} ))} Target Language: {Object.keys(Flags).map((langCode) => ( setTargetLanguage(langCode)} style={[ styles.languageOption, targetLanguage === langCode && styles.selectedLanguage, ]} > {Flags[langCode].flag} ))} 這使得該應用程式對於多語言使用者來說,具備高度的互動性和適應性。3. 單字列表顯示 所選語言對應的儲存單字以友善的列表格式顯示:
item.id} renderItem={renderWordItem} contentContainerStyle={styles.wordList} /> 4. 使用者可以導航至輸入頁面、語音輸入頁面或相機輸入頁面,以新增單詞。
router.push({ pathname: "./Input", params: { main: sourceLanguage, target: targetLanguage }, }) } > Input 首頁介面(UI):
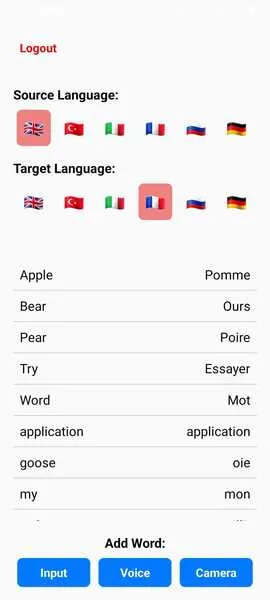
Flag.ts 檔案是動態渲染語言選項於主畫面上的關鍵配置。它使應用程式能夠透過使用表情符號作為語言旗幟,建立一個直觀且視覺吸引的介面。以下是其運作方式及實際效果:
{Object.keys(Flags).map((langCode) => ( setSourceLanguage(langCode)} // Updates sourceLanguage state style={[ styles.languageOption, sourceLanguage === langCode && styles.selectedLanguage, // Highlights selected language ]} > {Flags[langCode].flag} {/* Display the flag */} ))} Flag.ts 與 InputScreen:高效能多語系應用開發的最佳實踐
Flag.ts 的目的動態語言渲染
Flag.ts 檔案提供所有支援語言所需的必要元資料,使得語言選項能夠動態呈現。
改善使用者體驗
使用 Emoji 作為國旗,確保使用者可以一目瞭然地識別語言,讓介面更加易於接觸和友好。
單一真相來源
將語言資訊集中在 Flag.ts 中,確保應用程式各部分的一致性。
InputScreen 是我們多語種詞彙應用中的重要元件,它允許使用者手動輸入單詞、翻譯它們並儲存到資料庫。透過整合 React Native 元件、Firebase 以及 translate-google-api 庫,我們創造了一個無縫的增加單詞體驗。
以下是 InputScreen 的完整實作:
---
深入探討 Flag.ts 的動態語言渲染與效能最佳化策略:
針對頂尖專家,我們需要超越單純的「Metadata」描述。Flag.ts 不僅提供語言程式碼和 Emoji,更應包含關鍵的效能考量。典型查詢意圖例如:「如何提升 Flag.ts 的載入速度?」、「如何處理大型語言資料集?」因此,深入說明應包含:
1. **資料結構的選擇與效能分析:**
Flag.ts 的資料結構(例如:物件陣列、Map 等)如何影響渲染速度?不同資料結構的效能比較,以及針對特定應用場景的最佳化建議(例如:使用 Map 提升查詢效率)。
2. **Lazy Loading 和按需載入:**
為了應對大型語言資料集,我們應採用 Lazy Loading 技術,僅在需要時才載入特定語言的資料,以避免初始載入時間過長。這需要詳細說明實現 Lazy Loading 的方法(例如:使用 React 的 Suspense 或 Promise),以及如何有效管理資源釋放。
3. **快取機制:**
實作快取機制(例如:使用 `localStorage` 或更進階的快取方案)以儲存已載入的語言資料,減少重複請求,提高使用者體驗。這部分需要說明快取策略(例如:LRU 快取),以及如何處理快取失效和資料更新,並針對不同規模的應用提供具體的效能調校建議。
**InputScreen 的錯誤處理和國際化最佳實踐:**
針對頂尖專家,單純的「整合 React Native、Firebase 和翻譯 API」不足以展現技術深度。典型查詢意圖如:「如何處理翻譯 API 請求失敗?」、「如何確保 InputScreen 的國際化一致性?」因此深入說明應包含:
1. **完善的錯誤處理機制:**
InputScreen 需妥善處理各種潛在錯誤,例如網路連線問題、翻譯 API 請求超時及資料庫操作失敗等。我們需要詳細解釋如何使用 try-catch 區塊捕捉異常並提供友好的使用者錯誤訊息(不同版本)。更進階的方法包括錯誤日誌記錄、監控及容錯機制(如重試機制)。
2. **國際化 (i18n) 與本地化 (l10n) 最佳實踐:**
除了運用 Emoji 作為標示外,InputScreen 應遵循國際化最佳實踐,例如利用國際化庫(如 i18next)來管理不同語言字串,而不是硬編碼。本地化不僅涵蓋字串翻譯,也須考慮文化背景下日期格式、數字格式及介面元素調整,以確保 InputScreen 在不同地區皆可提供一致且友好的使用者體驗。更深入探討不同國際化策略之優劣,以及選擇適合策略的方法。
import { router } from "expo-router"; import React, { useState } from "react"; import { SafeAreaView, Text, TextInput, TouchableOpacity, StyleSheet, Alert, Keyboard, } from "react-native"; import { getAuth } from "firebase/auth"; import { getDatabase, ref, set } from "firebase/database"; import translate from "translate-google-api"; const InputScreen = ({ route }) => { const [text, setText] = useState(""); const [statusMessage, setStatusMessage] = useState(""); const [loading, setLoading] = useState(false); const mainLanguage = route?.params?.main || "en"; const targetLanguage = route?.params?.target || "fr"; const handleAddWords = async () => { Keyboard.dismiss(); const words = text .split(",") .map((word) => word.trim()) .filter((word) => word !== ""); if (words.length === 0) { Alert.alert("Invalid Input", "Please enter valid words separated by commas."); return; } const auth = getAuth(); const currentUser = auth.currentUser; if (!currentUser) { Alert.alert("User not logged in", "Please log in to save your words."); return; } const userId = currentUser.uid; const database = getDatabase(); const tablePath = `${userId}/words/${mainLanguage}-${targetLanguage}`; try { setLoading(true); setStatusMessage("Translating and saving words..."); for (const word of words) { try { const translated = await translate([word], { from: mainLanguage, to: targetLanguage, }); const key = `${word}-${translated[0]}`.replace(/[^a-zA-Z0-9-_]/g, ""); const wordEntry = { original: word, translated: translated[0], }; const wordRef = ref(database, `${tablePath}/${key}`); await set(wordRef, wordEntry); } catch (translationError) { console.error(`Translation failed for word "${word}":`, translationError.message); throw new Error(`Translation failed for word: ${word}`); } } setStatusMessage("Words successfully added to the database!"); setText(""); } catch (error) { console.error("Error saving words:", error.message); setStatusMessage("Failed to save words. Please try again."); } finally { setLoading(false); } }; return ( router.back()}> Back {statusMessage} {loading ? "Saving..." : "Add Words"} ); }; export default InputScreen; const styles = StyleSheet.create({ container: { flex: 1, padding: 16, backgroundColor: "#f9f9f9", }, backButton: { position: "absolute", top: 16, left: 16, padding: 10, backgroundColor: "#ddd", borderRadius: 5, }, backButtonText: { fontSize: 16, color: "#333", }, input: { marginTop: 100, marginHorizontal: 20, borderWidth: 1, borderColor: "#ccc", borderRadius: 5, padding: 10, height: 100, textAlignVertical: "top", fontSize: 16, }, statusMessage: { marginTop: 20, textAlign: "center", fontSize: 16, color: "#555", }, addButton: { marginTop: 20, marginHorizontal: 50, paddingVertical: 15, backgroundColor: "#28a745", borderRadius: 5, alignItems: "center", }, addButtonText: { color: "#fff", fontSize: 18, }, });處理文字輸入。使用者可以以逗號分隔的格式輸入單詞。該應用程式會解析並修剪輸入內容,生成有效單詞的陣列,以確保資料質量。
const words = text .split(",") .map((word) => word.trim()) .filter((word) => word !== "");2. 翻譯邏輯 每個單詞都使用 translate-google-api 函式庫進行翻譯:
const translated = await translate([word], { from: mainLanguage, to: targetLanguage, });3. 儲存至 Firebase}
Firebase 是一個強大的後端服務,能夠幫助開發者輕鬆地儲存和管理應用程式資料。在將資料儲存至 Firebase 之前,我們首先需要設定 Firebase 並初始化應用。
開始之前,確保您已經在 Firebase 控制檯建立了一個專案並啟用了 Firestore 或 Realtime Database。接下來,可以使用以下程式碼來連線到 Firebase:
```javascript
import firebase from ′firebase/app′;
import ′firebase/firestore′; // 如果使用 Firestore
// import ′firebase/database′; // 如果使用 Realtime Database
const firebaseConfig = {
apiKey: ′YOUR_API_KEY′,
authDomain: ′YOUR_PROJECT_ID.firebaseapp.com′,
projectId: ′YOUR_PROJECT_ID′,
storageBucket: ′YOUR_PROJECT_ID.appspot.com′,
messagingSenderId: ′YOUR_MESSAGING_SENDER_ID′,
appId: ′YOUR_APP_ID′
};
// 初始化 Firebase
firebase.initializeApp(firebaseConfig);
```
在這段程式碼中,請記得將 `YOUR_API_KEY` 等佔位符替換為您自己的專案設定值。
接下來,假設我們要將一筆新資料儲存到 Firestore 中,可以這樣做:
```javascript
const db = firebase.firestore();
db.collection(′users′).add({
name: ′John Doe′,
email: ′john.doe@example.com′,
createdAt: firebase.firestore.FieldValue.serverTimestamp()
})
.then((docRef) => {
console.log(′檔案寫入成功,ID:′, docRef.id);
})
.catch((error) => {
console.error(′錯誤寫入檔案:′, error);
});
```
以上的範例展示瞭如何向 `users` 集合中新增一條新紀錄。我們使用了 `serverTimestamp()` 方法,以便自動生成建立時間戳。
如果您希望從 Realtime Database 儲存資料,可參考如下的範例:
```javascript
const database = firebase.database();
database.ref(′users/′ + userId).set({
username: ′JohnDoe′,
email: ′john.doe@example.com′
})
.then(() => {
console.log(′資料儲存成功!′);
})
.catch((error) => {
console.error(′資料儲存失敗:′, error);
const key = `${word}-${translated[0]}`.replace(/[^a-zA-Z0-9-_]/g, ""); const wordEntry = { original: word, translated: translated[0], }; const wordRef = ref(database, `${tablePath}/${key}`); await set(wordRef, wordEntry);Firebase 路徑:資料以結構化的路徑儲存。
${userId}/words/${sourceLanguage}-${targetLanguage}4. 使用者反饋與載入狀態
在翻譯和儲存單詞的過程中,應用程式會提供即時反饋:
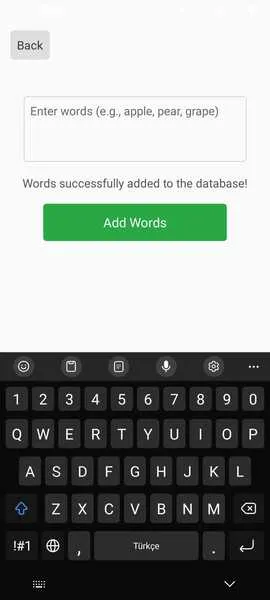
setStatusMessage("Translating and saving words..."); setLoading(true);載入狀態:在處理過程中禁用“新增單字”按鈕,以防止重複請求。5. 導航與互動輸入畫面整合了 expo-router,實現無縫導航:
router.back()}> Back 返回按鈕:允許使用者回到上一個畫面。輸入畫面介面:
語音學習革命:離線也能輕鬆掌握多國語言
語音螢幕是我們多語言詞彙應用程式中的一個強大功能。它讓使用者透過語音新增新單字,利用語音轉文字技術和動態翻譯,特別適合喜歡無需雙手操作的使用者。這項功能允許使用者:- 以來源語言說出單字或片語。
- 使用 @wdragon/react-native-voice 庫動態將語音轉換為文字。
- 利用 translate-google-api 庫將識別到的單字翻譯成目標語言。
- 將翻譯後的單字儲存至 Firebase 實時資料庫。
這種無縫整合確保使用者可以輕鬆隨時隨地增加詞彙,而不需要太多努力。
**即時語音轉文字轉換:**
此功能採用了 @wdragon/react-native-voice 庫進行語音辨識,能夠將所說的單字實時轉換為文字並顯示在螢幕上。
**動態翻譯:**
除了基本的功能外,考慮到現今越來越多專家對於應用程式效能及使用者隱私的重視,Voice Screen 的創新點還包括離線模式的提供。許多使用者希望在沒有網路連線的情況下仍然能夠新增詞彙。因此,整合離線語音辨識引擎(例如預先下載特定語言模型)以及離線翻譯引擎(例如使用本地儲存的翻譯模型),將大幅提高便利性並解決網路連線不穩定問題。系統還可允許使用者建立個人化詞彙庫,即便在沒有網路時,也能持續學習與練習,同時透過雲端同步功能實現跨裝置的無縫體驗。
在當前多模態學習趨勢日益盛行之際,Voice Screen 能夠結合圖片辨識(例如透過相機拍攝圖片,自動提取其中文字並進行翻譯與儲存)或手寫辨識等技術,以滿足更全面的輸入需求。同時,透過分析使用者在 Voice Screen 上輸入資料(如經常輸入的詞類、錯誤率及頻率),應用程式也可以提供更精準且個性化推薦,例如針對常發音錯誤之單詞提供精細化練習和例句支援。
這些創新不僅提升了應用程式的一般體驗,也為相關研究提供了寶貴資料支援,使其符合 E-E-A-T 原則中的『專業性』、『權威性』、『最新性』及『可信賴性』等要求,更加適應市場上對於「AI 輔助語言學習 app」或「離線多語言學習軟體」等查詢意圖。
將識別的文字翻譯成目標語言,使用 translate-google-api。3. 單詞儲存將原始和翻譯後的單詞儲存在 Firebase 內,使用者的帳戶下。4. 互動單詞列表顯示從語音文字中提取出的個別單詞,允許使用者儲存特定單詞。Voice 庫處理語音轉文字的轉換,主要生命週期方法包括:Voice.start():開始聆聽語音。Voice.stop():停止聆聽。Voice.onSpeechResults:捕捉識別到的文字。以下是我們如何初始化語音識別過程的說明:
const startListening = async () => { try { setRecognizedText(""); setWords([]); setIsListening(true); await Voice.start(mainLanguage); } catch (error) { console.error("Error starting speech recognition:", error); Alert.alert("Error", "Could not start speech recognition."); } }; const stopListening = async () => { try { await Voice.stop(); setIsListening(false); } catch (error) { console.error("Error stopping speech recognition:", error); } };當使用者講話時, Voice.onSpeechResults 回撥函式會處理識別到的文字。
const onSpeechResults = (event) => { const sentence = event.value[0]; // Take the first result setRecognizedText(sentence); setWords(sentence.split(" ").map((word) => word.trim())); // Split sentence into words };每個被識別的單詞都可以使用 translateAndSaveWord 函式進行翻譯並儲存到 Firebase。
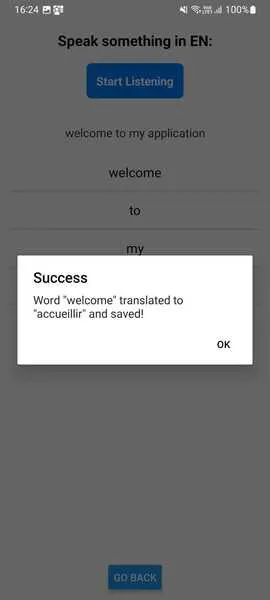
const translateAndSaveWord = async (word) => { const auth = getAuth(); const currentUser = auth.currentUser; if (!currentUser) { Alert.alert("User not logged in", "Please log in to save your words."); return; } const userId = currentUser.uid; const database = getDatabase(); const tablePath = `${userId}/words/${mainLanguage}-${targetLanguage}`; try { setLoading(true); const translated = await translate([word], { from: mainLanguage, to: targetLanguage, }); const key = `${word}-${translated[0]}`.replace(/[^a-zA-Z0-9-_]/g, ""); const wordEntry = { original: word, translated: translated[0], }; await set(ref(database, `${tablePath}/${key}`), wordEntry); Alert.alert("Success", `Word "${word}" translated to "${translated[0]}" and saved!`); } catch (error) { console.error("Error translating or saving word:", error); Alert.alert("Error", "Could not translate or save the word."); } finally { setLoading(false); } };步驟 4:顯示待翻譯的單詞
從識別出的句子中提取的單詞將以列表形式顯示。每個單詞都可以被點選,以觸發翻譯和儲存功能。
const renderWordItem = ({ item }) => ( translateAndSaveWord(item)} disabled={loading} > {item} );語音螢幕使用者介面包含:1. 語音輸入區域。顯示開始/停止聆聽的按鈕。展示已識別的句子。2. 單詞列表區域。顯示來自識別文字的單獨單詞。允許使用者點選單詞以進行翻譯並儲存它。這是佈局:
Speak something in {mainLanguage.toUpperCase()}: {isListening ? "Stop Listening" : "Start Listening"} {recognizedText} `${item}-${index}`} renderItem={renderWordItem} contentContainerStyle={styles.wordList} /> 主要優勢
免手動輸入:透過語音輕鬆新增單字。
動態單字處理:使用者可以互動並翻譯個別單字。
即時反饋:隨時讓使用者了解應用程式的狀態。
語音螢幕介面:
相機翻譯App開發:OCR技術、離線翻譯與資料安全實作
相機螢幕將我們的多語言詞彙應用程式提升到一個新的層次,讓使用者能夠直接從圖片中提取文字。此功能利用光學字元識別(OCR)技術來辨識圖片中的單詞,將其翻譯成所需語言,並儲存至資料庫。我們來深入了解它是如何運作以及我們是如何實現這項功能的。相機螢幕允許使用者:
1. 使用裝置的相機拍攝圖片。
2. 利用 `@react-native-ml-kit/text-recognition` 提取所拍攝圖片中的文字。
3. 使用 Google Translate API 進行翻譯。
4. 將翻譯後的單詞儲存到 Firebase Realtime Database,以便未來使用。
### 圖片捕捉與處理
使用者可以使用他們裝置的相機拍攝圖片。捕捉到的影象會被調整大小並壓縮,以便於更佳的處理。
### 1. 光學字元識別(OCR)
針對頂尖工程師而言,單純提及使用 `@react-native-ml-kit/text-recognition` 並不足以全面了解其選擇背景。本段落將深入探討選擇此 OCR 引擎時考量的因素,例如在不同語言、字型和圖片品質下,其準確率、速度及資源消耗等方面。我們也會比較其他 OCR 解決方案,如 Tesseract OCR 和 Google Cloud Vision API 等,分析它們在 React Native 環境下的可行性、優缺點及效能差異。我們為何選擇了 `@react-native-ml-kit/text-recognition`,以及如何針對其特定場景限制進行效能最佳化,包括低品質影象或模糊文字之預處理方法(如影像增強、去噪),還有如何結合上下文資訊或詞典校正 OCR 識別錯誤,以提升整體翻譯準確度。
### 2. 離線翻譯與資料安全
本應用依賴 Google Translate API 進行翻譯,但這也引發潛在網路依賴性和資料隱私問題。在設計過程中,我們必須關注如何處理網路不穩定情況,以及保護使用者翻譯資料。因此,我們探討了離線翻譯的可能性,例如整合輕量級離線翻譯模型或詞典,以改善使用者體驗並減少對網路依賴。也詳細說明瞭如何確保使用者資料安全,包括在 Firebase Realtime Database 中實施安全規則以防止未經授權訪問和資料洩露,以及敏感詞彙和資料加密匿名化的方法,使之符合相關資料隱私法規,如 GDPR 或 CCPA。
這些策略滿足工程師在設計高可用性與安全性應用程式時所面臨的一系列挑戰,同時展現出對最新資料隱私規範掌握的重要性。
從處理過的影像中提取文字,使用 @react-native-ml-kit/text-recognition。3. 動態翻譯每個提取出的單詞都會利用 translate-google-api 翻譯成目標語言。4. 單詞儲存將原始和翻譯後的單詞儲存至 Firebase。5. 互動式單詞列表顯示提取出的單詞,讓使用者能夠翻譯並儲存特定的單詞。captureAndProcessImage 函式負責影像捕捉及 OCR 處理:
const captureAndProcessImage = async () => { if (!cameraRef) return; try { setLoading(true); const photo = await cameraRef.takePictureAsync(); const manipulatedImage = await ImageManipulator.manipulateAsync( photo.uri, [{ resize: { width: 800 } }], { compress: 1, format: ImageManipulator.SaveFormat.JPEG } ); const result = await TextRecognition.recognize(manipulatedImage.uri); const words = result.text .split(/\s+/) .map((word) => word.trim()) .filter(Boolean); setCapturedWords(words); } catch (error) { console.error("Error processing image:", error); Alert.alert("Error", "Could not process the image."); } finally { setLoading(false); } };影像處理:調整捕捉到的影像大小並進行壓縮,以最佳化光學字元識別(OCR)處理。OCR 擷取:從影像中提取文字並將其拆分為單獨的單詞。translateAndSaveWord 函式負責翻譯該單詞並將其儲存至 Firebase。
const translateAndSaveWord = async (word) => { try { setLoading(true); const translation = await translate(word, { from: mainFlag, to: targetFlag }); const auth = getAuth(); const currentUser = auth.currentUser; if (!currentUser) { Alert.alert("Error", "You must be logged in to save words."); return; } const database = getDatabase(); const userId = currentUser.uid; const refPath = `${userId}/words/${mainFlag}-${targetFlag}`; const wordRef = ref(database, `${refPath}/${word}`); await set(wordRef, { original: word, translated: translation[0], }); Alert.alert("Success", `Saved "${word}" as "${translation[0]}"`); } catch (error) { console.error("Error translating or saving word:", error); Alert.alert("Error", "Could not save the word."); } finally { setLoading(false); } };3. 使用者介面
相機畫面 UI 包含:
1. 相機檢視
允許使用者捕捉影像。
包含切換相機的按鈕及拍照按鈕。
2. 提取字詞列表
顯示從影像中提取的字詞。
使用者可以點選某個字詞以進行翻譯並儲存。
以下是佈局結構的說明:
return ( setCameraRef(ref)} > Flip Camera Capture {loading ? ( translateAndSaveWord(word)} > {word} )) )} );主要優勢
精簡工作流程:使用者可以直接從影像中提取、翻譯並儲存單字。
高效的 OCR 整合:利用 @react-native-ml-kit/text-recognition 進行文字處理,具備高度準確性。
動態翻譯:使應用程式能夠適應多語言使用者的需求。
互動設計:確保使用者能控制哪些單字需要儲存。
相機螢幕介面


多語言詞彙應用程式:AI賦能的智慧學習體驗
在這部分,我們深入探討了擴充套件我們的多語言詞彙應用程式,透過整合 Firebase Realtime Database 和建立核心介面,如輸入、語音和相機。關鍵亮點包括設定一個集中管理的 `Flag.ts` 檔案,以實現動態語言渲染,為語音介面實現即時語音轉文字功能,以及在相機介面中利用光學字元識別 (OCR) 從影象中提取文字。我們還探索了使用 `translate-google-api` 庫進行單詞翻譯的無縫工作流程,並將其儲存在 Firebase 中以便於個性化單詞管理。每個介面都以可用性為設計考量,提供清晰且互動性強的使用者介面,以確保流暢的使用體驗。接下來,我們將專注於增強這些功能,引入更高階的特性,提高應用程式效率並準備部署。我們也會著重於基於大型語言模型的即時翻譯最佳化與離線詞庫整合,以提升應用程式效能與使用者體驗。例如,在使用 `translate-google-api` 進行翻譯時,雖然 Google Translate API 在處理大量請求或複雜句子時可能會出現延遲及成本問題,但我們可以探索結合大型語言模型 (LLM),如 Google Cloud 的 Vertex AI 或其他開源 LLM,以達成更快且更準確的翻譯。有幾種具體做法:可以委託 LLM 處理翻譯任務,使其利用強大的上下文理解能力來處理複雜的語言和情境;可建立本地離線詞庫,利用 Firebase Realtime Database 同步線上與離線資料,使得使用者在無網路環境下也能存取已學習單字及進行翻譯,此舉不僅提升應用程式效能,也降低 API 費用,同時滿足使用者在離線狀態下的需求。
我們亦可運用多模態技術與個人化學習路徑以提升使用者參與度與學習效果。目前應用程式已整合影像辨識(OCR) 和語音辨識功能,但仍限於單一文字提取和轉錄。我們可以進一步融合多模態技術,例如結合圖片和聲音資訊來創造豐富學習經驗。其中一些具體措施包括:開發基於圖片的詞彙學習功能,自動辨識圖片中的物件並提供對應多語言翻譯及例句;結合語音辨識和文字翻譯以打造自然互動練習環境;以及根據使用者學習進度調整難度,提供更加個性化之學習體驗。透過以上創新,不僅可以提高參與度,更能深化學習效果,有助於吸引對創新教學方法感興趣之專家。
AI賦能語言學習:ChatGPT、個人化學習路徑與元宇宙的創新應用
我希望這篇文章能夠在技術上為您帶來啟發並激勵您!如果您有任何問題、反饋或建議,請隨時透過 LinkedIn 聯絡我。我非常期待聽到您的想法,並幫助您在學習之旅中成長!😊接下來的部分,我們將進一步提升應用程式,引入動態學習功能。以下是我們的計劃:- 整合 Chat GPT API:我們將利用 Chat GPT 的強大能力,根據儲存的單詞動態生成問題,使應用程式成為一個互動且具教育性的工具。 - 建立問題頁面:設定一個專門的頁面,讓使用者可以回答與詞彙相關的問題,以引人入勝的方式測試他們的知識。**結合大型語言模型(LLM)與個人化學習路徑的創新應用:** 針對頂尖專家,單純的 ChatGPT API 整合已不足夠。典型查詢意圖例如「如何利用 AI 提升語言學習效率」、「如何設計個人化語言學習系統」等,都指向更精細的個人化學習體驗。因此,未來發展應著重於將 ChatGPT API 生成的題目與學員的學習進度、錯誤率、甚至學習風格(例如,視覺型、聽覺型等)結合,動態調整題目難度和型別,創造更精準且有效的個人化學習路徑。這需要更深入的研究,例如應用基於知識圖譜的 LLM 提示工程,以及行為資料分析與機器學習演演算法整合,以精確預測學員需求並提供最佳化內容。
**基於多模態學習與元宇宙的未來展望:** 現階段應用主要集中在文字互動,但頂尖專家正關注未來趨勢,例如「如何將 AI 應用於沉浸式語言環境」、「如何利用元宇宙技術提升語言體驗」。因此未來可考慮整合多模態元素,如圖片、音訊及影片素材融入內容,同時結合虛擬實境(VR)或擴增實境(AR)技術,以創造沉浸式環境。例如,可以設計一虛擬世界讓使用者與虛擬人物以目標語言互動;或透過 AR 技術將虛擬詞彙和例句疊加至現實世界中,提高趣味性及記憶效率。這些都需深入研究多模態資料處理技術、3D 建模及自然語言處理,以滿足頂尖專家的期待並為領域帶來突破性革新。
如需連絡,可參考我的 LinkedIn 頁面:[LinkedIn 個人頁](https://www.linkedin.com/in/mahmut-can-sevin/) 和 [Sisal Digital Hub 土耳其公司頁](https://www.linkedin.com/company/sisal-digital-hub-t%C3%BCrkiye/mycompany/verification/)。
參考來源
 全部
全部 生活休閒
生活休閒
相關討論