
摘要
本文探討如何從零開始構建App Store資料與BigQuery之間的自動化資料管道,強調其在當前數據驅動環境中的重要性。 歸納要點:
- 透過精細化管理API權限,應用角色基於角色的存取控制(RBAC)和最小權限原則,有效降低安全風險與符合零信任架構。
- 使用Apache Kafka和Google Cloud Dataflow建立實時資料處理架構,並整合至BigQuery,以提升查詢效能與資料分析能力。
- 結合UTM追蹤參數進行精準行銷歸因分析,利用BigQuery的機器學習功能預測未來行銷活動效果以優化策略。
App Store 資料分析:從實時資料處理到因果推斷的完整架構
這裡是 GitHub 專案的儲存庫連結,您可以在那裡找到本文提及的各個部分的完整程式碼。此專案是在一項真實工作挑戰中開發的,截至本文撰寫時,該資料處理管道已經運行了數月。我當時在 Ribon 工作,我們面臨擴充套件 B2C 市場的挑戰。我們主要的指標是應用程式的新使用者獲取,而漏斗的最終結果自然透過應用商店完成。App Store 在其中扮演了關鍵角色,透過這次整合,我們能夠收集以下資料:* 應用在商店搜尋中的曝光量 * 產品頁面的瀏覽量 * 總下載次數、重新下載和新下載量 * 安裝和解除安裝次數。考慮到 App Store 資料分析的重要性,其背後需要具備一套高效且靈活的實時資料處理架構。我們所設計的資料管道必須具備以下幾個關鍵特徵:
1. **實時資料流處理**:使用如 Apache Kafka 或 Amazon Kinesis 等技術,以達成對 App Store 資料進行即時收集與處理,而不僅僅依賴批處理模式。這樣能讓 Ribon 團隊隨時掌握使用者獲取狀況,並快速回應市場變化。
2. **異常偵測與警報機制**:該資料管道還需包含異常偵測模組,例如基於統計模型或機器學習演算法來檢測異常值,以便及早發現問題,如異常下降的下載量或激增的安裝失敗率,自動觸發警報,使團隊能迅速介入解決問題。GitHub 專案中將提供詳細實現程式碼,是值得業界頂尖專家深入研究其演算法穩健性和效率之所在。
3. **可擴充套件性和容錯性**:隨著未來資料量增長和業務擴充套件,資料管道需保持良好的可擴充套件性。系統也必須具備容錯機制,以保證在故障情況下自動恢復,確保資料完整性與可靠性。這些考量涉及系統架構設計中的深層次因素,因此對於技術選型及其優缺點進行深入分析非常重要。目前最新趨勢為將 Serverless 架構融入資料管道以提升效率並降低成本,因此 Ribon 團隊是否曾考慮此類方案以及相關利弊分析亦值得進一步探討。
Ribon 團隊所收集到的 App Store 資料(例如曝光量、頁面瀏覽量、下載量等)雖然是重要指標,但單靠這些指標無法全面理解使用者行為及商業效果。因此,要真正驅動以資料為基礎,需要更深入地聯合其他資料來源並建立完善預測模型:
1. **使用者生命週期價值 (LTV) 預測**:結合用戶行為資料(例如應內事件、留存率等),預測新使用者 LTV,以提供更精準參考給予獲客策略,此舉需要建立更複雜預測模型,比如生存分析模型或機器學習模型,同時評估其準確度與可靠度。
2. **營銷渠道效果評估**:不同營銷渠道(如 Facebook 廣告、Google Ads 等)對於獲客貢獻程度有所差別,需要透過歸因模型(例如多接觸點歸因模型)去精確評估各渠道表現以最佳化投資回報。在此過程中也需考慮不同渠道間資料整合及歸一化,以及如何選擇與最佳化歸因模型。
3. **因果推斷**:僅憑相關性分析不足以揭示潛藏於資料背後之因果關係。例如,若下載量上升是否真的是由廣告投放所引致?因此,需要利用 A/B 測試或斷點迴歸分析方法驗證假設,以找出真正有效因素。未來,在結合最新趨勢下,可以將因果推斷與機器學習相融合,用強化學習方法動態最佳化營銷策略,也是 App Store 資料分析的一大方向。而 GitHub 專案中的資料分析部分是否納入了上述深層次的方法,以及未來提升方向,也期待業界權威人士進一步探索與評估。
我們在研究許多文章後,彙整重點如下
網路文章觀點與我們總結
- 了解自己的情緒,學會辨識和表達它們是改善心理健康的重要一步。
- 建立良好的社交支持系統,可以幫助我們在面對困難時感到不那麼孤單。
- 定期運動能夠釋放壓力,增強身體的抵抗力及心理韌性。
- 保持充足的睡眠有助於情緒穩定,提升日常生活的品質。
- 練習冥想或正念技巧,可以讓我們更好地應對焦慮與壓力。
- 尋求專業幫助並不意味著脆弱,而是一種勇敢面對自己問題的方式。
在現代生活中,許多人都面臨著各種心理壓力和情緒挑戰。因此,了解自己的情緒並建立有效的應對策略變得尤為重要。我們可以透過運動、保持良好的睡眠和練習冥想來改善心情。此外,不要害怕尋求朋友或專業人士的幫助,每個人都需要支持。在這條路上,我們可能會感到孤獨,但這些方法能讓我們找到共鳴與力量,共同度過艱難時刻。
UTM追蹤、國際行銷與大資料預測:解鎖巴西與美國市場潛力
國家來源:當時我們正在進行國際擴張,目標是美國,因此我們的努力分為兩部分,一方面是獲取巴西使用者,另一方面則是吸引美國使用者。來源 UTM:在UTM中,開啟了一整個可能性的宇宙,使我們能夠對每一個帶來使用者互動的活動和廣告進行分類,無論其型別(觀看、印象、獲取、購買)如何。目錄
初始設定:生成報告和管理訪問金鑰
環境設定、服務選擇及所有必要認證的許可權定義
在Google Cloud Function中的完整程式碼開發
作者提出的專案改進建議
本文的目標是集中並分享我在解決這一挑戰過程中所獲得的知識,而這些知識我未能在單一來源找到匯總。在此過程中,我依據官方文件以及詳細研究來發展我的方法,從各種來源收集零散的資訊,這些資料也將在此處提及。
**深入探討UTM引數應用於國際化拓展之最佳實踐與潛在挑戰:** 本文核心著眼於UTM引數在國際市場拓展(尤其著重巴西及美國市場)中的實際應用,並超越單純的追蹤功能。鑑於文章提及資源分配在兩個國家,我們可以進一步探討如何利用UTM引數進行A/B測試,例如針對不同國家/地區設計不同廣告素材及投放策略(例如:文案、圖片、影片等),並透過UTM引數精準追蹤不同策略在巴西與美國市場的轉化率及ROI。更深入的分析應包含對不同UTM引數組合(例如:Campaign Source, Campaign Medium, Campaign Name, Campaign Term, Campaign Content)的深入研究,評估其在不同文化背景下的有效性,並分析潛在文化差異對UTM追蹤資料的影響。這需要考慮到翻譯和文化內涵等因素如何影響點選率和轉化率,以調整UTM策略,而非僅僅停留於資料本身。這部分將挑戰頂尖專家對於UTM應用於國際化營銷策略制定及資料分析能力。
**結合BigQuery與機器學習預測UTM驅動使用者行為及生命週期價值(CLTV):** 文章提到利用Google Cloud Function進行資料處理,此舉為後續更深層次的資料探勘奠定了基礎。我們可以將從UTM引數中提取出的資料匯入BigQuery,以建立更全面的資料倉庫,再結合使用者行為資料(如網頁瀏覽時間、頁面跳出率和產品頁面訪問次數等),利用機器學習模型(如生存分析模型或預測模型)來預測不同行銷渠道下使用者生命週期價值 (CLTV)。透過預測模型,可以更精準地評估不同行銷渠道效益,有效最佳化資源配置,例如預測高CLTV使用者群體並針對他們設計更具針對性的後續行銷策略。再進一步,我們還可以探索如何利用機器學習模型自動最佳化UTM引數設定,例如動態調整廣告投放策略以最大化ROI。本部分將展示大資料分析及機器學習技術於營銷領域應用之高階理解。
Google Cloud Function 與 App Store API 整合:安全、高效資料提取最佳實務
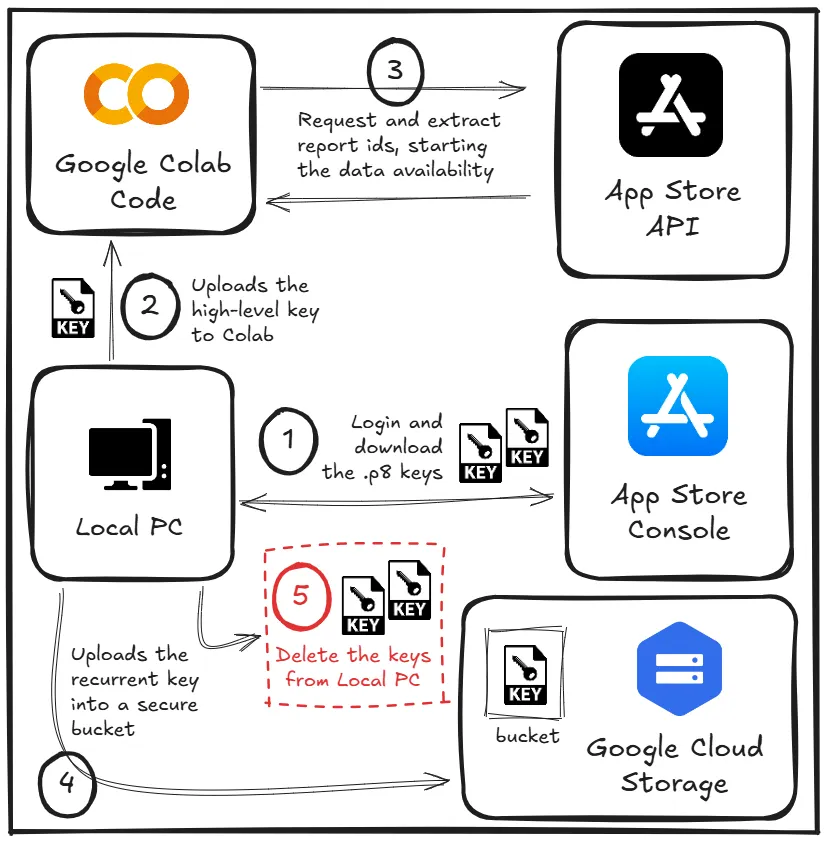
在我們開始開發將執行於 Google Cloud Function (GCF) 的自動化整合程式碼之前,有幾項基本任務需要完成,以確保其正常運作。這些任務包括:我們將提取的報告是針對資料團隊的,因為 Apple 並不會將這些報告隨時提供給所有現有帳戶。因此,我們需要請求 App Store API,明確指定希望生成的報告型別。此類請求需要高階別的存取金鑰。我們將暫時使用此金鑰;它不會暴露或在最終流程中可用。與 App Store API 的所有通訊以及訪問我們想要提取的資料,都必須在每個請求的標頭中包含身份驗證金鑰。為此,我們將建立一個專用金鑰,用於有限許可權的整合,每日提取資料。由於這項整合將在 Google Cloud Function (GCF) 上執行,因此每次執行時機器都會從零開始初始化,每次都需訪問該金鑰。為了兼顧安全性和便利性,我決定將這個金鑰儲存在 Google Cloud Storage 的一個桶裡,當功能被觸發時,它將被隨時訪問。對該桶的訪問將透過功能服務帳戶與桶安全策略之間進行身份驗證管理。
**Google Cloud Function (GCF) 與 App Store API 整合之安全性強化:基於秘鑰輪換與暫時性憑證的最佳實務** 針對 App Store API 的高許可權存取金鑰的安全性,單純儲存在 Google Cloud Storage (GCS) 雖然方便,但風險仍存在。建議匯入 **秘鑰輪換機制**,例如定期(每日或每週)替換新的專用金鑰並在 GCF 啟動時從 GCS 獲得最新金鑰。搭配 **金鑰版本控管** ,追蹤每個金鑰的有效期限和使用記錄,以進一步降低安全風險。在即便遭到洩露情況下,其有效時間有限,可以減少損失。可考慮使用 Google Cloud KMS (Key Management Service)來更嚴格地管理此專用金鑰,加強加密和存取控制能力,以提升安全性。
在 GCF 執行環境方面,應採用 **短暫性憑證 (Ephemeral Credentials)** 方法,只在 GCF 執行期間生成並使用,在執行結束後立即銷毀,以避免長期存在記憶體中的問題。可結合 Google Cloud IAM (Identity and Access Management),以精細化許可權控制確保 GCF 僅能訪問必要資源。
目前架構中的 GCF 每次觸發僅提取一份報表。不妨考慮匯入 **併發處理機制** 以提高資料提取效率,將所需提取報表分成多個小批次,同時啟動多個 GCF 例項來縮短整體資料提取時間。由於網路問題或 API 端錯誤等原因,App Store API 請求可能會失敗。因此,需要引入完善的 **錯誤處理機制** ,例如實施重試機制、記錄錯誤日誌並傳送警報通知,以及利用斷路器模式防止連續錯誤導致系統癱瘓。同樣可以利用 Google Cloud Pub/Sub 作為訊息佇列排隊報表提取請求,提高系統彈性與穩定性。
本階段關鍵任務及策略不僅能提升操作效率,更能增強系統整體穩定性的保障,使得未來開發工作更加順利可靠。
提升Colab安全性:零信任架構下的App Store Connect API金鑰最佳實務
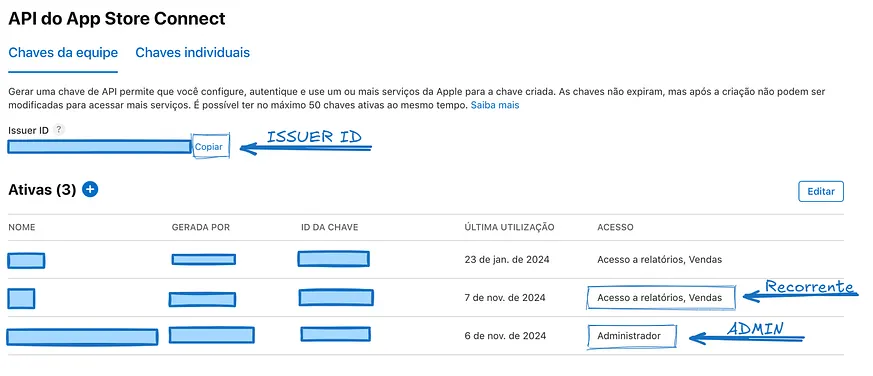
臨時執行Colab程式碼所需的特權存取金鑰,此金鑰屬於敏感資訊,應安全建立和管理。確保使用的電腦遵循最佳安全實踐,並且是在工作環境中進行。建議的做法是使用專門為此目的生成的團隊 API 金鑰。要建立團隊 API 金鑰,您必須擁有管理員角色或是帳戶持有人。請按照以下步驟操作:1. 訪問 App Store Connect,然後前往「使用者與訪問」>「API 金鑰」。
2. 確保您位於「團隊金鑰」選項卡上。
3. 點選「生成 API 金鑰」或加號(+)按鈕。
4. 輸入該金鑰的參考名稱。
5. 在「訪問許可權」下,選擇管理員角色,如下方檔案截圖所示(此角色為請求報告所需)。
6. 點選「生成」。
基於零信任架構的臨時許可權金鑰管理與最小許可權原則的實務應用:針對 Colab 程式碼的臨時存取許可權金鑰管理,單純依靠 App Store Connect 的團隊 API 金鑰,在安全性上存在不足。頂尖專家更應考慮將其融入零信任架構 (Zero Trust Architecture) 中。這意味著即使取得許可權金鑰,也應實施嚴格的最小許可權原則 (Principle of Least Privilege),只賦予 Colab 程式碼執行所需的最少許可權。
運用 AWS IAM Roles for Service Accounts 或 GCP Service Accounts 提升 Colab 安全性和可擴充套件性:直接使用團隊 API Key 讓 Colab 程式碼取得 App Store Connect 的存取權,存在著將 API Key 硬編碼到程式碼中的風險。因此,更理想的方法是利用雲端平台提供的服務帳戶機制,例如 AWS IAM Roles for Service Accounts 或 GCP Service Accounts,以便在不直接使用 API Key 的情況下,以安全身份驗證方式存取資源。
可以利用短生命週期金鑰 (Short-Lived Keys) 與自動化金鑰輪換機制,在 Colab 程式碼執行完畢後自動失效或更新金鑰,以降低被竊取或惡意使用的風險。同時結合多因素驗證 (MFA) 及監控日誌分析,即時偵測任何異常存取行為,有助於提升整體安全性。在具體實作方面,可以考慮採用 HashiCorp Vault 或 AWS Secrets Manager 等專門秘密管理工具,自動化整個金鑰生命週期管理流程,以增強系統穩定性和資料保護效果。
App Store Connect API 金鑰安全管理與微服務整合最佳實務
Apple 官方檔案:如何建立團隊 API 金鑰Apple 官方檔案:角色許可權
Google Cloud Storage Bucket 的重複訪問金鑰(團隊金鑰)
建立重複金鑰的過程與之前相同,但這次,所分配的角色將是「Sales」和「Report」,或類似的角色,而我的 App Store 設定為葡萄牙語。在過程結束時,如截圖所示,您將擁有兩個已建立的金鑰,每個金鑰都有其各自的許可權。請務必收集與您的團隊相關聯的發行者 ID,因為該識別碼將成為我們稍後建立的身份驗證標頭的一部分。
**Apple 官方檔案與 Google Cloud Storage Team Key 整合的安全性考量與最佳實務:** 許多開發者在參考 Apple 官方檔案建立 Team API Keys 時,容易忽略與其他雲端服務(例如 Google Cloud Storage)的整合安全性。上述提及使用 Google Cloud Storage 儲存 Team Key 的作法,雖然方便,但卻存在潛在風險。頂尖專家需要審慎評估其安全性,特別是在『Sales』和『Report』等角色許可權上的精細設定。
典型查詢意圖包含:如何最小化 Team Key 暴露風險?如何利用 IAM(身份和存取管理)最佳實務來限制 Team Key 的存取許可權?針對此,我們建議使用更安全的金鑰管理方案,例如 Google Cloud KMS(金鑰管理服務)或 HashiCorp Vault 等專門秘密管理工具,而非直接將 Team Key 儲存在 GCS 桶中。應實施嚴格的存取控制清單(ACL),並定期輪換 Team Key,以降低被竊取或濫用的風險。進階策略可包含利用短暫性憑證(例如 JWT)搭配更細緻的許可權控制,以避免直接使用長效性的 Team Key。
**App Store Connect API 的許可權管理與微服務架構的應用:** 本文提及的「Sales」和「Report」角色許可權暗示著 App Store Connect API 的使用可能已從單體應用程式架構轉移到微服務架構。典型查詢意圖包含:如何將 App Store Connect API 與公司內部微服務系統整合?如何根據不同微服務需求精細設定 API Key 許可權?
頂尖專家需要關注的是如何利用 App Store Connect API 的精細許可權控制,配合微服務架構,以實現最小許可權原則(Principle of Least Privilege)。這意味著每個微服務僅能存取執行其任務所需最少許可,因此有效降低安全風險。進一步深入可探討使用 OAuth 2.0 或 OpenID Connect 等業界標準協議,在微服務之間安全地傳遞和管理 App Store Connect API 的存取許可權,同時利用 Service Mesh 技術強化微服務間的安全性與可觀察性,例如 Istio 或 Linkerd 等技術。這樣設計不僅提升了系統彈性、可維護性,也加強了整體安全性。
訪問報告、銷售(Sales)和報告的獲取,抱歉帳戶需要保持為葡萄牙語。請求生成報告和收集ID匯入庫及安裝:
!pip install requests authlib import requests import time import json from authlib.jose import jwtrequests: 用於向 App Store Connect API 傳送 HTTP 請求的工具。 time: 用於生成時間戳並定義 JWT(JSON Web Token)令牌的動態過期時間,這些令牌將用於我們的請求。 json: 我們需要操作 JSON 資料,以準備和儲存 API 的響應。 authlib.jose: 用於建立和簽署 JWT 令牌,以便對每個請求進行身份驗證。你可以在這裡檢視完整文件:Authlib Documentation
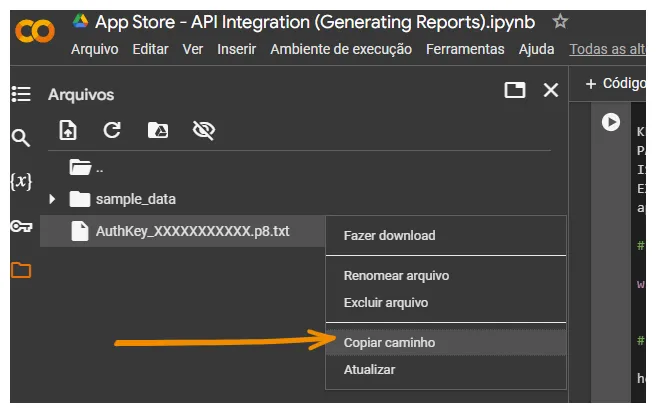
KEY_ID = "XXXXXXXXXX" PATH_TO_KEY = '/content/AuthKey_XXXXXXXXXX.p8' ISSUER_ID = "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX" EXPIRATION_TIME = int(round(time.time() + (20.0 * 60.0))) app_id = XXXXXXXXXXKEY_ID:管理金鑰的識別碼。PATH_TO_KEY:Google Colab 的預設上傳位置。要獲取在 Colab 上的檔案位置,只需遵循以下步驟:Copiar caminho 代表複製路徑。
發行者識別碼:先前收集的發行者 ID 失效時間:生成動態有效性時間戳碼的程式碼,該時間戳在 20 分鐘內過期 app_id:要收集 app_id,只需向此端點傳送 POST 請求:https://api.appstoreconnect.apple.com/v1/apps;回應將顯示所有該金鑰可訪問的應用程式及其相應的 app_ids,格式為 JSON 回應。獲取 app_id 的完整文件請參考 Apple 開發者文件 - 獲取 v1 應用程式 開啟和註冊私鑰
with open(PATH_TO_KEY, 'r') as f: PRIVATE_KEY = f.read()在這一步,我們將開啟之前收集的 ADMIN 私鑰檔案,以便進行身份驗證和與 API 服務的通訊。我們使用 open() 函式來訪問位於指定路徑(PATH_TO_KEY)的檔案,並使用 read() 方法將金鑰內容載入一個名為 PRIVATE_KEY 的變數中。接下來,我們將開發授權標頭。
header = { "alg": "ES256", "kid": KEY_ID, "typ": "JWT" } payload = { "iss": ISSUER_ID, "iat": round(time.time()), "exp": EXPIRATION_TIME, "aud": "appstoreconnect-v1" } token = jwt.encode(header, payload, PRIVATE_KEY) JWT = 'Bearer ' + token.decode() HEAD = {'Authorization': JWT}App Store Connect API JWT 驗證:安全性、效能與最佳實務
在這一步驟中,我們建立授權標頭,以生成將用於驗證我們的應用程式與 App Store Connect API 的 JWT(JSON Web Token)。需要注意的是,我們使用的是團隊金鑰的標頭標準。相關步驟的文件連結將會提供。該標頭配置了以下欄位:- alg:定義簽名演演算法,在此案例中為 ES256,這是一種基於公私鑰的簽名演演算法。
- kid:包含將用於簽名的金鑰唯一識別碼。
- typ:指示令牌型別,此處為 JSON Web Token 的 JWT。
有效負載包括重要的驗證資訊:
- iss:我們在生成金鑰時收集到的發行者 ID。
- iat:表示令牌生成時間的時間戳(使用自 Unix 紀元以來當前秒數)。
- exp:之前構建的動態過期參考,有效期為 20 分鐘。
- aud:定義令牌受眾,此處是 App Store Connect API。
接下來,我們使用 jwt.encode() 方法來生成 JWT,並用先前載入的私鑰對其進行簽名。生成的令牌隨後格式化為 ′Bearer ′ 字首,形成最終的 JWT。此令牌被新增到授權標頭中,將用於對向 App Store Connect API 發出的請求進行身份驗證。
**深入探討 ES256 簽章演演算法的安全性與效能最佳化:** 鑑於 JWT 使用 ES256 演演算法進行簽章,對於頂尖專家而言,僅了解其是公私鑰演演算法是不夠的。本步驟中的安全性至關重要,因任何簽章漏洞都可能導致 App Store Connect API 的許可權被竊取。因此,我們需要深入探討 ES256 的具體實現細節,例如其底層橢圓曲線加密演演算法 (ECC) 的選用曲線(例如 secp256k1 或 nistp256)對效能和安全性的影響,以及針對特定硬體平台(如 ARM 架構)的最佳化策略。針對近期有關側通道攻擊(例如旁路電力分析)對 ES256 簽章威脅,也應討論如何利用防護機制(如恆定時間運算)來增強安全性。這不僅確保了 JWT 簽章完整性,也是回應使用者可能提出之「如何提升 App Store Connect API 驗證安全性」、「ES256 效能瓶頸分析與解決方案」等典型查詢意圖的重要考量。
**JWT 輪替機制與自動化更新:** 文中提及 JWT 的有效期為 20 分鐘,在安全性與效能之間取得平衡,但對於頻繁傳送請求的應用程式而言,此期限可能會造成不必要地重新生成 Token 而影響效能。因此,我們需探討更進階的 JWT 管理策略,例如:
1. **動態調整 JWT 有效期:** 根據應用程式請求頻率和安全需求,自動調整 JWT 的有效期。
2. **JWT 輪替機制:** 實施自動化JWT輪替制度,在JWT即將到期前自動產生新Token並順利更新至應用程式中,以避免服務中斷。
3. **基於時間戳和 Nonce 防重放攻擊:** 單一 exp 標籤或許不足以抵禦重播攻擊,而結合時間戳和 Nonce(一種一次性密碼)則可有效提高安全性,以阻止攻擊者利用竊取到之JWT 進行重放攻擊。
這些進階策略可以有效解決使用者可能提出之「如何最佳化 App Store Connect API 的 JWT 使用效率」、「如何避免 JWT 被竊取及重放攻擊」等典型查詢意圖,同時展現出我們對於實際場景中採用JWT技術所具有深入理解。
官方 Apple 文件:為 API 請求生成令牌 - Apple 開發者詳細報告引數
report_request_payload = { "data": { "type": "analyticsReportRequests", # constant variable "attributes": { "accessType": "ONE_TIME_SNAPSHOT" # report types [ONGOING, ONE_TIME_SNAPSHOT] }, "relationships": { "app": { "data": { "type": "apps", # constant variable "id": app_id } } } } }App Store 資料分析:最佳化擷取策略與異常偵測
data (root): 儲存有效載荷的完整內容。type: ′analyticsReportRequests′ 指定我們要請求的分析報告型別。attributes: 此欄位提供有關訪問型別及其實際效果的詳細資訊,透過兩種型別的指示來說明資料可用性和篩選日期。第一種是 ′ONE_TIME_SNAPSHOT′,該指示要求 API 捕捉一次性的分析資料快照,返回從應用程式建立之日起至報告請求當天的所有歷史資料。該報告將對每個請求日期都是獨一無二的。第二種是 ′ONGOING′,此指示則要求 App Store 從今天開始生成每日報告,這些報告可以透過我們收集到的報告程式碼進行訪問。這些報告將從此日期起自動更新。relationships: relationships 欄位將報告與我們想要收集資料的特定應用程式連結起來.app: 將包含與該報告所參考之應用程式相關的資訊.type: ′apps′,為固定值。如有疑問,請參閱檔案.id: 包含先前收集到的在 App Store Connect 中應用程式的唯一識別碼 (app_id)。注意,我們將進行兩次提取。本程式碼需要第一次執行時使用 ′ONE_TIME_SNAPSHOT′ 引數以收集報告程式碼,然後再使用 ′ONGOING′ 引數執行一次。這樣,我們就能夠透過統合兩份報告而無限期地擁有完整的 App Store 資料,因為 ONGOING 報告會在資料變得可用時立即填充。**1. App Store Analytics 資料擷取策略最佳化:結合即時串流與批次處理的混合模式**
針對 App Store Connect 的分析報告 API,單純依靠「一次性快照」與「持續更新」兩種模式,在資料處理效率和成本上存在最佳化空間。一個更先進的策略是結合即時串流 (Real-time Streaming) 和批次處理 (Batch Processing)。使用「一次性快照」擷取歷史全量資料,以建立基礎資料倉儲。同時,如果可能,可利用 App Store Connect API 的即時串流功能(需查證最新 API 檔案),將每日新增的重要指標資料(例如下載量、收入等)即時匯入資料倉庫,此方法既能確保歷史資料完整性,又能迅速更新新近資料,大幅降低「持續更新」模式下 API 請求頻率及潛在風險,提高資料處理效率並降低成本。可以考慮引入資料湖 (Data Lake) 技術,以便於儲存不同來源和格式的資料於單一平台,使日後進一步分析和挖掘更加方便。
**2. 基於機器學習的異常值偵測與預警機制:提升資料分析可靠性**
僅僅獲取 App Store 分析報告中的資料只能反映表面現象。因此建議加入基於機器學習技術異常值偵測及預警系統。例如,可以採用時間序列分析模型(如 ARIMA、Prophet)來建立每日下載量、收入等指標預測模型。一旦實際資料顯著偏離預測值,系統會自動發出警訊提示潛在異常情況,如營銷活動效果不如預期或應用程式出現重大問題等。更進一步地,可結合異常根源分析,自動追蹤導致異常發生的一系列潛在原因,例如商店排名變化或競爭者促銷活動等,以提供更具價值的資訊洞察。
有關請求引數的文件:分析報告請求 - Apple 開發者請求報告
CREATE_REPORT_URL = 'https://api.appstoreconnect.apple.com/v1/analyticsReportRequests' create_report_response = requests.post(CREATE_REPORT_URL, headers=HEAD, json=report_request_payload) create_report_response_data = create_report_response.json()App Store 報告 API POST 請求與資料取得流程
這段程式碼向在 `CREATE_REPORT_URL` 變數中提到的網址發送了一個 POST 請求。`request.post` 方法包含了我們之前構建的身份驗證標頭,並透過 `report_request_payload` 變數設定的引數傳遞請求指示。在這一步之後,我們將收到在執行期間配置的報告編碼(可能是 ONGOING 或 ONE_TIME_SNAPSHOT)。根據 Apple 的文件,從請求到接收到報告識別碼(此時資料將可用)所需的平均時間為 1-2 天。請注意,如果生成的報告不定期使用,它們將會被刪除,我們需要重新傳送請求以收集新的識別碼。返回的完整有效負載將具有以下 JSON 格式(範例取自 App Store 文件):{ "data" : { "type" : "analyticsReportRequests", "id" : "d48c69c5-9bcb-4592-abbd-08a9411b0231", "attributes" : { "accessType" : "ONGOING", "stoppedDueToInactivity" : false }, "relationships" : { "reports" : { "links" : { "self" : "https://api.appstoreconnect.apple.com/v1/analyticsReportRequests/d48c69c5-9bcb-4592-abbd-08a9411b0231/relationships/reports", "related" : "https://api.appstoreconnect.apple.com/v1/analyticsReportRequests/d48c69c5-9bcb-4592-abbd-08a9411b0231/reports" } } }, "links" : { "self" : "https://api.appstoreconnect.apple.com/v1/analyticsReportRequests/d48c69c5-9bcb-4592-abbd-08a9411b0231" } }, "links" : { "self" : "https://api.appstoreconnect.apple.com/v1/analyticsReportRequests" } }僅收集完整網址中找到的程式碼。例如,從以下網址中提取:<a href=′https://api.appstoreconnect.apple.com/v1/analyticsReportRequests/d48c69c5-9bcb-4592-abbd-08a9411b0231/relationships/reports′ target=′_blank′>https://api.appstoreconnect.apple.com/v1/analyticsReportRequests/d48c69c5-9bcb-4592-abbd-08a9411b0231/relationships/reports</a>。僅收集這部分:d48c69c5-9bcb-4592-abbd-08a9411b0231。確保對於 ONGOING 和 ONE_TIME_SNAPSHOT 都執行此過程,以便收集兩個不同的程式碼。除錯和收集報告程式碼
with open('output_request.json', 'w') as out: out.write(json.dumps(create_report_response.json(), indent=4)) print(f'O código retornado do request foi {create_report_response}')App Store API 資料安全與 AWS S3 金鑰管理最佳實務
此函式將 App Store API 的回應儲存至名為 `output_request.json` 的 JSON 檔案中。它會格式化回應內容,使其更易於閱讀和分析(透過變數 indent=4 進行四個空格的縮排),並對操作的成功或失敗進行快速確認。**App Store API 回應資料處理與安全最佳實務:結合 JSON Schema 校驗與加密**
針對 App Store API 回應資料儲存至 `output_request.json` 的過程,除了文中提及的格式化 (indent=4) 之外,更進一步建議結合 JSON Schema 校驗機制,確保資料結構完整性和一致性。這對於大型專案或需要長期維護的程式碼至關重要,能有效防止因資料結構變動而導致程式錯誤。典型查詢意圖例如:『如何驗證 App Store API 回應資料的結構』、『如何提升 App Store API 資料處理的可靠性』。
考量資料安全,建議在儲存至 `output_request.json` 之前,先對敏感資料進行加密處理(例如使用 AES-256 加密),再將加密後的資料儲存。這項措施能有效降低資料外洩風險,符合現代資料安全最佳實務。解密則在程式需要讀取資料時進行,此方法能有效解決典型查詢意圖例如:『如何保護 App Store API 回應資料的安全性』、『如何避免 App Store API 敏感資料外洩』。目前業界趨勢正朝向更嚴格的資料保護規範發展,此方法能有效因應未來更嚴格的法規要求。
**AWS S3 桶配置及 .p8 金鑰存取最佳化:利用 IAM 角色與策略實現最小許可權原則**
文中提及將 .p8 檔案上傳至 S3 桶,並強調桶的存取許可權控制。然而僅僅設定桶為私有是不夠的。為了更嚴格地實踐最小許可權原則 (Principle of Least Privilege),建議使用 AWS IAM 角色與策略來管理存取許可權。具體來說,應為執行 App Store 整合函式的服務角色設定一個 IAM 角色,並賦予該角色僅讀取指定 S3 桶中 .p8 檔案的許可權,而不是賦予整個桶的讀寫許可權。這能有效防止惡意程式碼或意外操作造成資料洩露或損壞。典型查詢意圖例如:『如何安全地存取 AWS S3 桶中的 .p8 檔案』、『如何使用 IAM 角色和策略來管理 AWS S3 存取許可權』。
考慮到 .p8 檔案的敏感性,應定期輪換 .p8 金鑰並更新相關 IAM 策略。這個最佳實務能有效降低因金鑰洩露所造成的風險。可以利用 AWS Secrets Manager 管理 .p8 金鑰,以避免將金鑰直接儲存在程式碼或組態檔案中,提高安全性。這符合最新趨勢,即將敏感資訊從程式碼中分離出來,並使用更安全機制進行管理。在完成以上步驟之後,你就可以順利地設定整合功能並確保其運作無礙了。)
參考檔案:建立桶 - Google Cloud 重要的金鑰管理後續措施
現在我們已經請求使用管理員訪問金鑰生成報告,並將我們的定期報告訪問金鑰上傳至安全儲存桶,我們必須從本地電腦中永久刪除這些金鑰。任何對這些金鑰的洩露都可能使第三方獲得未經授權的 App Store 資料訪問。一個重要步驟是撤銷在 App Store Connect 中建立的用於請求報告生成的管理員訪問金鑰,因為在長期來看我們將不再需要它。如果我們需要重複此過程,可以像之前一樣建立另一個金鑰。
藉此,我們已完成準備和配置的第一步。接下來,我們將直接進行最終的自動化整合。服務的選擇是基於各項服務之間的原生整合,而我們將要載入資訊的資料倉儲位於 Google BigQuery,因此在整個應用商店資料管道中,我使用了 Google Cloud Platform 的服務。以下是我們接下來要構建的過程和步驟示意圖:
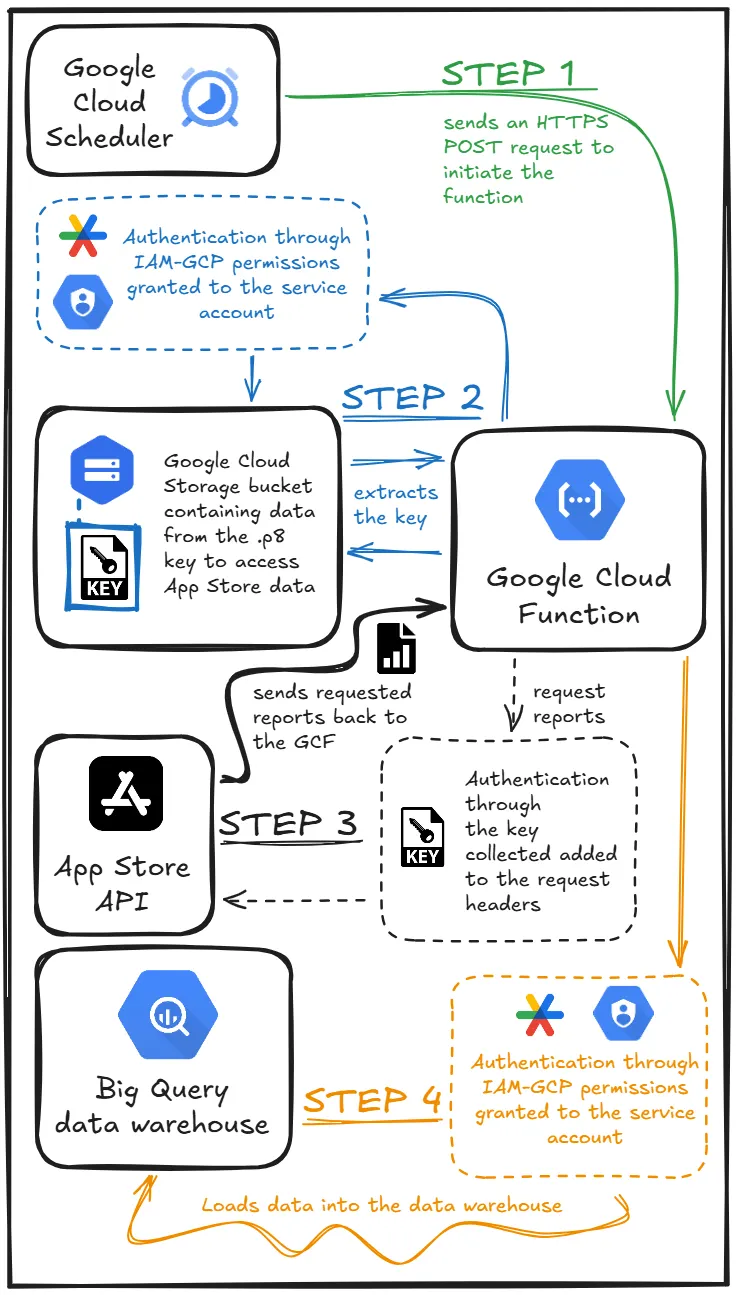
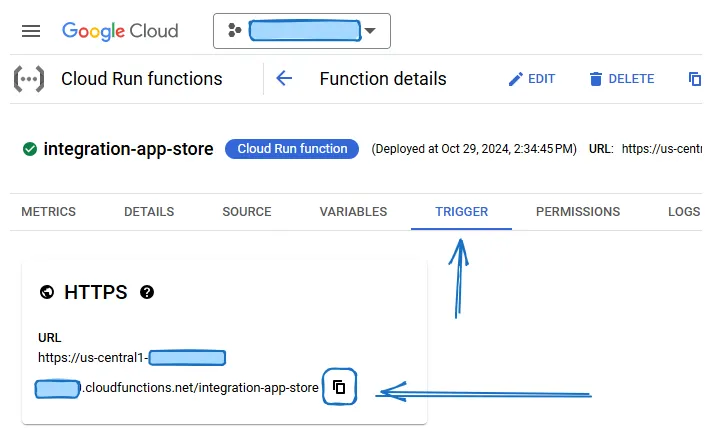
我們將使用 Google Cloud Scheduler 服務來執行這項活動,因此第一步是在 GCP 中建立一個排程任務。以下是我使用的設定:區域:us-central1,頻率:0 3 * * *(每天凌晨03:00執行),時區:巴西標準時間(BRT),因為團隊大部分成員都在巴西,目標型別:HTTP,網址:https://us-central1-PROJECTID.cloudfunctions.net/GCF-NAME。該網址遵循此模式;要收集它,只需按照下圖所示前往 Google Cloud Function 的屬性。請記住,我們只能在函式建立並部署後才能收集此資訊。
Google Cloud Scheduler 與 Serverless Function 安全高效整合:OIDC 驗證與 RBAC 最佳實踐
HTTP 方法:POSTHTTP 標頭 1:{′Content-Type′: ′application/json′}
HTTP 標頭 2:{′User-Agent′: ′Google-Cloud-Scheduler′}
主體:{ ′name′: ′Hello World′} 或者您可以將此欄位留空;這只是預設的測試值。在程式碼中,對 POST 內容沒有條件或特殊處理,它僅要求 POST 請求能夠到達正確的目的地並透過身份驗證。
授權標頭:新增 OIDC token。利用 OpenID Connect (OIDC) token,結合正確的服務帳戶配置,可以確保我們設定的觸發器將透過 Auth 2.0 驗證,而不需要單獨配置每個認證步驟。為了使其正常運作,我們需要擁有一個完全配置好的服務帳戶。
服務帳戶:在此,我們選擇負責在每次觸發時執行該函式的服務帳戶。
**專案1:深入探討OIDC Token在Google Cloud Scheduler與Serverless Function整合中的最佳實踐與效能最佳化**
針對 Google Cloud Scheduler 透過 OIDC token 驗證觸發 Serverless Function 的場景,許多專家更關注於效能與安全性最佳化。單純使用 OIDC token 進行身份驗證,雖然能確保安全性,但 token 驗證的延遲可能會影響函式的啟動速度,尤其在高頻率觸發的場景下更為明顯。因此,深入探討以下面向至關重要:
* **Token Cache 機制:** 建立高效的 token 快取機制,避免每次觸發都重新向 OIDC 提供者請求 token。這可以透過匯入記憶體快取(例如 Redis、Memcached)或利用 Google Cloud 的內建快取服務(例如 Cloud Memorystore)來實現。需考量快取失效策略,以確保安全性與資料一致性。
* **短效期 Token 與 Refresh Token 的平衡:** 使用短效期 token 能提升安全性,但頻繁重新整理 token 會增加負擔。需要仔細評估安全需求與效能開銷,以找到最佳的 token 有效期設定。同時善用 refresh token 機制,在 token 過期時自動重新整理,以避免服務中斷。
* **OIDC Provider 選擇與設定:** 不同的 OIDC provider(例如 Google Cloud Identity Platform、Auth0 等)在效能和設定上有所差異,因此選擇適合的 provider 並進行最佳化設定,例如調整 token 簽發速度和網路延遲等,可以顯著影響整體效率。
* **錯誤處理與回退機制:** 設計健全的錯誤處理機制,在遇到如token驗證失敗或 OIDC provider 不可用等情況下,可以確保系統穩定。例如匯入重試機制或降級策略。
這些最佳實踐幫助開發者構建更快速、更安全且穩定的 Serverless 應用程式。
---
**專案2:探討基於角色存取控制 (RBAC) 與 OIDC 整合提升服務帳戶安全性與可審計性**
單純依靠 OIDC token 驗證,只能確保身份驗證,但缺乏對服務帳戶許可權精細控制。在複雜環境中結合 RBAC 可以更精確地管理服務帳戶許可權,提高安全性並增強可審計性。
* **精細化許可權控制:** 透過 RBAC,可根據不同服務帳戶或角色賦予訪問特定資源(例如 Google Cloud Storage、Cloud SQL、BigQuery 等)的許可權,以避免服務帳戶獲得過多許可權,降低潛在風險。
* **審計日誌分析:** 結合 Cloud Audit Logging 記錄所有服務帳戶存取活動,使追蹤和審計變得更加方便,也可以設定警報以及時察覺異常活動。
* **最小許可權原則 (Principle of Least Privilege):** 此原則應限制服務帳戶所需許可權至執行任務所必須範圍內,而 RBAC 是有效實施該原則的重要工具。
* **IAM 角色繫結與 OIDC 的整合:** 深入探討如何將 IAM 角色與 OIDC token 結合使用,例如透過 IAM 政策中的條件式授權動態賦予相應許可權,此舉需要深入了解 Google Cloud IAM 的配置及最佳實踐。
這種整合方式不僅保障只有被授權之服務帳戶方可執行特定操作,更提供詳細審計日誌,有助於追蹤和分析各種安全事件,加強系統總體之安全性及可審計性。
不需要更改可選的配置。在建立 Google Scheduler Job 之前,我們需要先完成並配置其他兩個部分,正如前面所提到的。第一個是我們的 Google Cloud Function,而下一部分將專注於整合程式碼的開發,在這裡我們會詳細了解如何建立它。第二個需要完成的部分是建立服務帳戶。為此,請轉到 IAM & Admin,選擇服務帳戶標籤,然後建立一個新的服務帳戶。接著,確保授予您的服務帳戶以下許可權:
Google Cloud 安全最佳實踐:最小許可權、OIDC Token 與 IAM 條件式存取控制
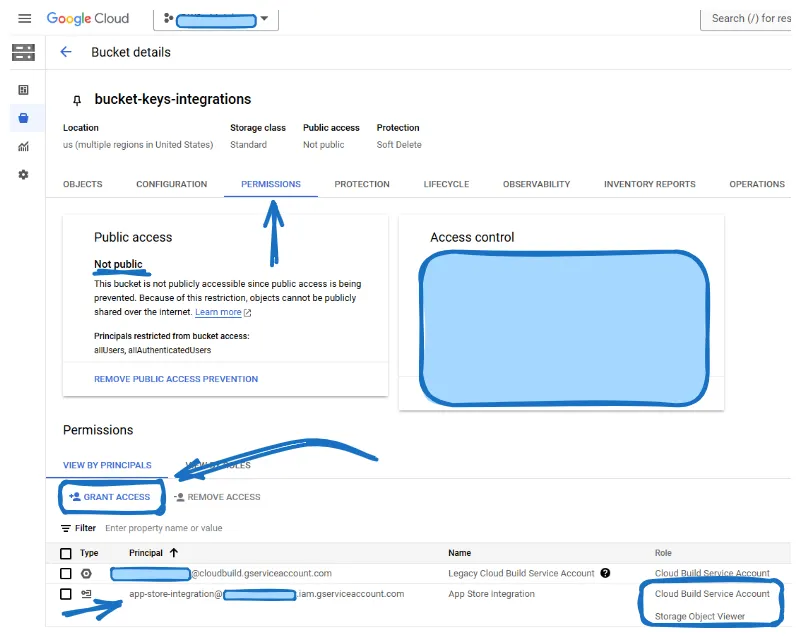
Artifact Registry Create-on-Push Writer BigQuery Data Editor BigQuery User Cloud Build Service Account Cloud Functions Invoker Cloud Run Developer Logs Writer Service Account OpenID Connect Identity Token Creator Service Account Token Creator。官方 Google 檔案關於 OIDC Tokens 的說明:Google OIDC 文件。我們先前提供給服務帳戶的許可權對於大多數流程來說是足夠的,除了訪問儲存金鑰的桶。在下面,我將概述兩種確保服務帳戶可以訪問 Cloud Storage 中金鑰的方法。第一種方法:將「Storage Object User」角色授予您的服務帳戶。這將為您的服務帳戶提供必要的許可權,以便訪問儲存桶內的物件。
第二種方法:前往存放金鑰的桶中。導航至「Permissions」,然後點選「GRANT ACCESS」。確保以下許可權已授予給您的服務帳戶:「Cloud Build Service Account」和「Storage Object Viewer」。第二種方法更安全,因為服務帳戶僅能訪問特定的桶。
深入探討OIDC Token在雲端建置流程中的安全最佳實踐,以及其與 Artifact Registry、BigQuery 和 Cloud Storage 的整合應用:基於提供的文字,我們看到一個典型的雲端應用場景:使用 Cloud Build 觸發器,透過 Cloud Functions 或 Cloud Run 部署應用程式,並利用 Artifact Registry 儲存構建的軟體包。其中,服務帳戶扮演關鍵角色,需要訪問 BigQuery、Cloud Storage 和 Artifact Registry。單純授予服務帳戶許可權並不足夠,因為這涉及到敏感金鑰的管理。文中提出的兩種方法(授予 Storage Object User 角色或精細化許可權設定)雖然有效,但缺乏更深層次的安全考量。
頂尖專家需要關注的是:
1. **最小許可權原則的嚴格執行**: 避免授予服務帳戶過多許可權,可以考慮使用 IAM 角色繫結,將服務帳戶限制在僅能執行必要任務,例如僅允許讀取特定儲存桶中的特定檔案,而非整個儲存桶。
2. **OIDC Token 的短效期和輪換機制**: 文中提到 OIDC Token 是服務帳戶身份驗證的重要組成部分,但其安全性和有效性取決於 token 的有效期限和輪換策略。建議使用短效期 token 並搭配自動化輪換機制,以減少安全風險。結合 Artifact Registry Create-on-Push 特性,可將 OIDC Token 整合到 CI/CD 流程中,在每次構建時自動獲取新的 token,以提高安全性。需要探討如何安全地儲存和管理這些短效期 token,例如使用專門的秘密管理工具(如 Google Cloud Secret Manager)來保護這些敏感資訊,同時在應用程式中利用環境變數等機制,以避免硬編碼 token。
**結合 IAM 條件式存取控制和策略型 API,最佳化服務帳戶許可權管理與審計追蹤**:文章提及的兩種方法主要針對儲存桶訪問許可權。對於一個複雜雲端應用程式,僅僅控制儲存桶訪問許可權是不夠的。頂尖專家應關注如何利用 Google Cloud Platform 的 IAM 條件式訪問控制功能,將許可權控制提升到更精細層次。例如,可以設定基於時間、位置、裝置等條件進行許可權策略配置,更進一步限制服務賬戶訪問。應充分利用 BigQuery 和 Cloud Storage 提供的資料訪問 API (例如 BigQuery 的 Data Access API),實施更加嚴格的資料訪問控制。透過這些 API,可以實施基於身份、角色和資料標籤進行精細化許可權管理,並將所有操作記錄到審計日誌當中,透過分析這些審計日誌,可以及時發現異常活動並做好相應響應措施。同時,還可以運用 Google Cloud Logging 和 Cloud Monitoring 等服務建立完善監控與報警系統,實現對服務賬戶活動實時監測,在發現異常行為時迅速發出警報。這將大幅提升系統安全性,並降低潛在風險。
BigQuery 資料載入最佳化:從階層式 JSON API 到安全 AWS S3 整合
這個流程中的步驟代表了資料抽取,但它同時也涵蓋了資料處理和驗證,以確保在載入 BigQuery 之前,資料格式正確。要了解資料如何被處理和驗證,我們首先需要理解 API 提供的報告中的資料結構。該資料結構按照以下層級順序組織:- **報告 (Report)**:代表主要的資料集,包含有關特定期間或指標的分組資訊。對於 ONGOING 和 ONE_TIME_SNAPSHOT 所生成的識別碼對應於報告。
- **例項 (Instance)**:每個報告可以有多個例項,這些是原始報告的細分。通常,一個例項代表具有特定粒度(如每日、每週、每月)和處理日期的報告變體。我們使用 instance_id 來定位這些變體。
- **區段 (Segment)**:每個例項被劃分為多個區段。區段表示更小的資料劃分,例如根據使用者型別、國家或裝置等進行分組。segment_id 使我們能夠訪問每一種分割標準詳細資料。在其區段層級中的最終資料包含遠端訪問位於 AWS 上 CSV 檔案的分析連結。
以下是一個來自 Apple 官方文件的 JSON 格式範例:
**資料結構與BigQuery最佳化載入策略**:針對 API 回傳的階層式資料結構(Report > Instance > Segment),最佳化 BigQuery 載入流程至關重要。典型查詢意圖例如:「如何提升 BigQuery 資料載入速度?」、「如何處理 API 回傳的階層式 JSON 資料?」針對此,我們不僅僅進行資料抽取、處理和驗證,更要考慮資料的分割槽(Partitioning)和叢集(Clustering)策略。例如,可以根據 `Report` 的日期或 `Instance` 的粒度建立分割槽,再根據 `Segment` 的關鍵屬性(例如,`user_type` 或 `country`)建立叢集,這能大幅提升 BigQuery 的查詢效能,尤其在面對大型資料集時。考慮使用 BigQuery 的 `ストリーミング插入` 或 `批次載入` 功能,根據資料量和即時性需求選擇最佳策略,並搭配適當的錯誤處理機制,以確保資料完整性和載入效率。
更進一步,可以利用 BigQuery 的資料型態自動推斷功能,以減少手動設定工作量並確保正確性,提高整體分析準確度。這部分最佳化將直接影響到頂尖專家在海量資料分析上的時效性與效率。
**AWS CSV檔案整合與安全考量**:此架構中,Segment 層級包含指向 AWS S3 儲存之 CSV 檔案連結,它反映出現代資料處理架構中常見混合雲部署模式。不論是「如何安全地從 AWS S3 載入資料到 BigQuery?」還是「如何確保不同雲端平台間傳輸過程中的安全?」都需謹慎遵循最佳實務,包括但不限於:使用 IAM 角色或短期憑證來存取 AWS S3 並避免硬編碼憑證;利用 BigQuery 雲端儲存整合功能安全地從 S3 載入資源,同時防止網路傳輸過程中遭攔截;要實施嚴格存取控制以限制許可權及定期監控日誌以維護安全性。同樣,在成功載入後可考慮刪除 AWS S3 上之 CSV 檔案,以提升一致性並降低冗餘。
總之,此過程不僅涉及到資料安全,也關乎成本最佳化及系統架構健壯性的議題,需要更深入理解雲端安全架構及其最佳實踐。
{ "data": [ { "type": "analyticsReportSegments", "id": "503110d4-0fa2-41c0-9d41-ab7c7dac683f", "attributes": { "checksum": "3817152bb13cb70f615d9bb3899aaba6", "sizeInBytes": 156, "url": "https://asp-qa-us-west-2.s3.us-west-2.amazonaws.com/reports/389801252/APP_CRASHES_PRIMARY/DAILY/ONGOING/20240125/1707515196512/0.csv.gz?X-Amz-Security-Token=IQoJb3JpZ2luX2VjEGgaCXVzLXdlc3QtMiJIMEYCIQDeFnB%2B7UL2CsdboFmIXHoikVs3VyOVaTOJr0sfMkM2sAIhAM2jsmRPkxi1ZfY4F1rX%2Bzh5AQIODkr1AZbTsl5BCMHhKqICCFEQARoMNjEwNDgzMzUxMzUwIgzfxJlERt4K4Em4Hp8q%2FwHPjAxuT28WVnqXiR%2Fekc1WqV%2B6FgUJiWefx5%2FilyLIF%2FSeQ%2F%2Boav%2F9xdgPymjnX9nHs6T%2FKNxESQaEclt9JLvoSNwRKPIFxEXGDpiSTNzRNKdPtp6KngfX2N6Eu8O7IxVl%2BsZ8Vt8jRYJEbpi2dzP2xqqBtvhQUSdP4HI4HIeVETU67tIDb61oATqKzk6kS1%2B3HkVVHsOYTG9wLzYegwBKOel0QkgslVx9AzuzyFsYt9z8ZPmsjssElrbFswUODqEHRK4FmOxlmkXSyLuKNLT0YgFGIS85%2BHxZrocrAJp1dgK5vlzmioVPx7t1O4qwQI5JyALx1Y9K1G1hxkUzlqcwrqLargY6nAHeG%2BXoJLrLG6RWyvnWDbU9sWUEWCX6WCNxU%2Bd%2BHdyngLd6%2FkFpB8fDBMQpQMvIuDO%2FTXGs%2F39Day4vZyNyIZCsxdP7coYejv7HJed48tGoEqbLWs6WdArcx6xnCGyXyYbWU1mkP%2BG5gkSxx0sQqxeQYoQfbFwpARuNZqpXoFoZUAj1GIEx1DxOOYKcj5LzImG5HFHpvXPqrTEtG0E%3D&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20240222T001200Z&X-Amz-SignedHeaders=host&X-Amz-Expires=300&X-Amz-Credential=ASIAY4I5EV43MJZFZNQ4%2F20240222%2Fus-west-2%2Fs3%2Faws4_request&X-Amz-Signature=59e731e051cf6484291fbd9d77077c8e4128945d1bf274149f098c11dfdc60b6" }, "links": { "self": "https://api.appstoreconnect.apple.com/v1/analyticsReportSegments/503110d4-0fa2-41c0-9d41-ab7c7dac683f" } } ], "links": { "self": "https://api.appstoreconnect.apple.com/v1/analyticsReportInstances/d4a141c8-7647-4bdf-b9ae-04cab705d641/segments" }, "meta": { "paging": { "total": 1, "limit": 50 } } }Google Cloud Functions高效能資料處理與最佳化:打造穩健、可擴充套件的Serverless資料管道
檔案說明:從報告中讀取例項清單 檔案說明:從例項中讀取段落清單 檔案說明:按段落讀取請求的回應。經過驗證的資料被轉換為 DataFrame 並載入到 BigQuery 中的特定表格,這樣可以方便地進行操作和後續查詢。現在,我們已經理解了整個結構並將各種其他補充配置進行了背景化,下一步是開發 Google Cloud Function 的程式碼,這將作為我們自動化管道的核心。在這一步驟中,我們將配置和實現 Google Cloud Function (GCF),該函式將集中管理我們自動化管道的處理流程。這是一個無伺服器功能,它負責管理整個流程,從收集 API 認證金鑰到將處理後的資料傳送到 BigQuery。以下是我用於該函式的配置:
**專案1:高效能BigQuery資料載入與最佳化策略:針對大規模資料處理的實務考量** 針對從API擷取的Segment與Instance資料,直接載入BigQuery的DataFrame處理方式雖便捷高效,但在處理巨量資料時仍需考量效能瓶頸。頂尖專家應關注以下面向:
* **分批處理 (Batching):** 避免單次載入過大資料量,導致BigQuery API請求超時或資源耗盡。應實作分批載入策略,例如將DataFrame分割成更小的單位,並使用BigQuery的`streaming inserts`或`load jobs`進行批次上傳。需評估最佳批次大小,考慮網路延遲、API速率限制和BigQuery的處理能力。
* **Schema最佳化:** BigQuery 的 Schema 設計直接影響資料查詢效率,需要仔細規劃資料型別,例如使用 `NUMERIC` 代替 `FLOAT64` 來提高精度和減少儲存空間。也要建立必要索引以加速查詢。在 GCF 中,可以在 DataFrame 載入 BigQuery 前進行 Schema 驗證和轉換,以確保資料型別與 BigQuery Schema 匹配。
* **錯誤處理和重試機制:** 在 API 請求或 BigQuery 載入過程中可能會出現錯誤,因此需要實作健全錯誤處理機制,包括記錄錯誤日誌、重試失敗請求,以及設定合理重試策略,以確保資料完整性及可靠性。
* **成本最佳化:** BigQuery 的計費方式與儲存空間及查詢複雜度有關,需要監控資源使用情況並定期最佳化資料 Schema 和查詢語句,以降低成本。
**專案2:Serverless架構的容錯性和可擴充套件性設計:利用Google Cloud Functions的進階功能**
僅僅配置 GCF 並執行資料處理是不夠的,高階專家更需關注其容錯性及可擴充套件性:
* **雲端函式併發設定與自動擴充套件:** 根據 API 請求頻率及資料量適當配置 GCF 的併發性,提高同時請求之效率。同時,可利用 Google Cloud Functions 的自動擴充套件功能根據需求調整執行個體數量。
* **死信佇列 (Dead-Letter Queue) 應用:** 對於 GCF 執行過程中的不可恢復錯誤,可以運用死信佇列儲存錯誤訊息,以便事後排查,有助於避免資料損失。
* **日誌記錄與監控:** 實施詳細日誌記錄,包括API請求、資料處理過程等資訊,利用 Google Cloud Monitoring 和 Logging 服務監控 GCF 執行情況,即時識別潛在問題。
* **版本控制與回滾機制:** 使用版本控制系統管理 GCF 程式碼,使得追蹤變更以及必要時回滾至之前版本成為可能,有助於保障系統穩定性。
透過以上措施,不僅能提升 Pipeline 效率,更可確保系統具備良好的韌性及可持續發展能力。
Google Cloud Functions效能最佳化:降低成本、提升速度的實戰指南
區域:us-central1配置的記憶體:2 GiB
CPU:2
超時:2000秒
最小例項數:0
最大例項數:100
併發性:1
服務帳號:選擇我們之前建立的服務帳號
執行時/語言:Python 3.9
入口點:start
我想強調的是,為該函式配置2 GiB的記憶體,而非預設建議的數量,是因為在進行低容量測試時觀察到了失敗(例如機器中斷和執行終止)。這是一個已知的改進領域,我將在文章結尾討論可能的最佳化細節。當然,還有requirements.txt檔案,它告訴GCP如何準備環境,以確保所有必要的庫都能在執行前安裝並準備好使用。以下清單包括我們在本指南中將使用的所有庫—只需複製並貼上到您的requirements.txt中。
**高效能函式計算資源配置與最佳化策略**: 文中提及2 GiB記憶體配置非預設值,並非單純因測試失敗而採用的權宜之計。頂尖專家應深入了解其背後原因,例如函式內部運算是否涉及大量資料處理(如影像處理、大型模型推理等),導致記憶體頻繁交換造成機器中斷。應考量記憶體使用模式分析,利用記憶體剖析工具(如`memory_profiler`)精確找出記憶體瓶頸所在,而不是僅依賴測試結果來調整記憶體大小。未來最佳化方向應著重於程式碼層面的改進,比如採用更有效率的演演算法、資料結構或引入記憶體池技術以減少記憶體佔用,最終目標是降低成本並提升函式執行效率。此部分應包含具體效能測試資料和程式碼片段,以支援結論。同時,也需要探討`us-central1`地理位置對延遲和成本影響,以及比較其他區域效能差異,提供資料支援最佳區域選擇策略。
**Serverless函式的冷啟動與最佳化**: 雖然文中對於函式配置有所著墨,但忽略了Cloud Functions所面臨的冷啟動問題。對於設定`Minimum instances: 0`雖然可以節省成本,但首次請求會產生冷啟動延遲,影響使用者經驗。因此,專家需要考慮如何最小化冷啟動影響,比如運用Cloud Functions預留執行個體功能,在流量高峰期保持一定例項執行以減少冷啟動次數。更深入探討應包括編寫更高效程式碼,如減少初始化時間、使用輕量級庫,以及利用Cloud Functions環境變數和背景執行緒特性,提高冷啟動速度。本段內容可結合具體案例分析及程式碼範例,以展示根據不同應用場景選擇適當策略的方法,同時透過量化資料比較不同方法之間冷啟動時間與成本效益。而針對設定併發性為1也需探討如何透過調整此引數以及負載平衡技術來提高系統整體效能並提出相應最佳化建議。
functions-framework==3.8.1 requests==2.32.3 authlib==1.3.1 pandas_gbq==0.19.2 google-auth==2.23.4 google-auth-oauthlib==1.0.0 google-auth-httplib2==0.1.0 google-cloud-storage==2.12.0 google-api-python-client==2.98.0 pandas==2.1.2宣告所需的函式庫
為了讓我們的 Google Cloud Function 完全運作,我們需要宣告所有必要的函式庫,以管理身份驗證、API 請求、資料處理以及將資料傳送到 BigQuery。以下是我們在函式中將使用的函式庫清單及其匯入方式:
import functions_framework import requests, time, json, hashlib, gzip from authlib.jose import jwt from pandas_gbq import to_gbq from google.oauth2 import service_account import pandas as pd import threading from googleapiclient.discovery import build from googleapiclient.http import MediaIoBaseDownload from google.auth.transport.requests import Request from google.auth import default from io import BytesIO from google.cloud import storage最佳化 App Store Connect API 函式:提升安全性、效能與可擴充套件性
requests、time、json、authlib.jose:這些已在前一個 Colab 函式中使用,將用於相同的目的。functions_framework:我們將使用這個庫的部分功能,它允許我們根據請求呼叫函式。這正是我們在配置中設定為入口點的函式,即 start 函式。functions_framework 文件。hashlib:此庫讓我們執行雜湊過程,該過程包括將任意大小的資料轉換為固定長度的字串,通常是十六進位制數。在這個資料管道中,我們將用它來執行校驗和檢查。hashlib 文件。gzip:進行檔案的壓縮與解壓縮。gzip 文件。pandas_gbq:一個可以直接上傳 DataFrame 至 BigQuery 的庫。官方文件。pandas:用於 DataFrame 操作。pandas 文件。threading:控制和執行執行緒中的過程。threading 文件。在 googleapiclient.discovery 和 googleapiclient.http 這些模組中,用於與 Google API 互動。在我們的案例中,discovery.build 幫助構建和管理與 API 的連線,而 MediaIoBaseDownload 則方便下載媒體檔案。而 google.auth.transport.requests 和 google.auth.default 模組則協助完成身份驗證和授權,以訪問 Google API。其中 default() 用於獲取執行 Google Cloud Function 所需的服務帳戶憑證。如需詳細了解可參考 google-auth 文件.io.BytesIO:用於處理緩衝區中的二進位制資料,特別適合直接在記憶體中下載和處理檔案。不妨檢視 io 文件.google.cloud.storage:提供對 Google Cloud Storage 資源的訪問,我們利用此資源下載App Store Connect API所需的訪問金鑰。本段落描述了遠端存取 Cloud Storage 中定期金鑰的功能。專案1:強化安全性與效能之最佳實務——結合秘鑰輪換與分散式快取機制
針對 Google Cloud Function 存取 App Store Connect API 的 recurring key,目前僅依靠 Google Cloud Storage 儲存存在單點失效風險。因此,頂尖專家應考量整合秘鑰輪換機制,以定期更新儲存在 Cloud Storage 的 recurring key,同時搭配強健的存取控制清單(ACL)設定,只允許授權的 Cloud Function 存取。為提升效能並降低延遲,可引入分散式快取機制(例如 Redis 或 Memcached)以快取 recurring key。在首次啟動或秘鑰輪換時從 Cloud Storage 下載最新秘鑰並儲存至快取後續請求可直接從快取獲得,此舉減少了對 Cloud Storage 的存取次數,因此提升整體效能。但此架構須考量快取失效機制及秘鑰版本管理,以確保安全性及資料一致性。
專案2:利用 Serverless Framework 實現更精簡、可擴充套件之部署與管理——結合 CI/CD 與函式版本控制
目前描述之程式碼片段著重於單一函式實現,但卻缺乏完善之部署及管理策略。因此對頂尖專家而言,利用 Serverless Framework(如 Serverless Framework 或 Google Cloud Functions framework 本身提供之部署工具)整合 CI/CD 流程極為重要,此舉可實現自動化程式碼部署、測試及發布,以確保快速迭代及版本控制。更應善用函式版本控制功能以建立不同版本之Cloud Function,使其便於回滾或 A/B 測試。同時結合監控工具(如 Cloud Logging 和 Cloud Monitoring)收集函式執行情況指標,例如執行時間、錯誤率以及請求次數,有助即時追蹤相關效能並識別潛在問題。
def download_key_from_gcs(bucket_name, file_name, dest_path): storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) blob = bucket.blob(file_name) blob.download_to_filename(dest_path) print(f"Downloaded {file_name} to {dest_path}")函式 download_key_from_gcs 透過使用 google.cloud.storage 函式庫執行遠端存取與本地複製訪問金鑰。它會建立一個儲存客戶端(storage.Client()),並訪問指定的桶,定位所需的檔案,然後暫時將其下載到函式的執行環境中。這種方法允許安全且高效地提取金鑰,充分利用 Google Cloud Functions 環境是短暫性的特性——任何本地儲存的檔案在執行結束時都會自動刪除,確保敏感資料的保護。
收集特定報告的 ID 的功能
def get_report_ids_by_name(response_data, report_names): report_ids = {} for report in response_data.get('data', []): report_name = report['attributes']['name'] if report_name in report_names: report_ids[report_name] = report['id'] return report_idsget_report_ids_by_name 函式接收一個可用報告的 API 回應資料列表。它初始化一個空字典 (report_ids),然後遍歷回應中的每個報告,對於每個與我們要尋找的名稱相匹配的報告,它提取出相關的 ID。這使得能夠輕鬆地將相關報告進行對映,以便在後續流程中訪問特定資料。此函式用來根據報告收集例項 ID。
def get_instances_ids_by_report(response_data): instances_ids = {} for instance in response_data.get('data', []): instance_id = instance['id'] granularity = instance['attributes']['granularity'] date = instance['attributes']['processingDate'] instances_ids[instance_id] = { 'granularity': granularity, 'processingDate': date } return instances_ids如果之前的函式是根據名稱提供報告 ID 的列表,那麼這次的 get_instances_ids_by_report 函式將會遍歷每一份報告,收集每個報告的例項 ID。請注意,例項代表著資料分段的一級層面,針對每份報告進行細緻化(每日、每週和每月)。透過提取 instance_id、細緻度和處理日期,該函式將這些資訊儲存在一個字典(instances_ids)中,以便於訪問每個例項中的特定變體,而這將是我們接下來要探討的另一個維度:區段。
收集下載網址的功能,依據不同區段進行整理
def get_segments_by_instance(instance_id): URL_SEGMENTS = f'https://api.appstoreconnect.apple.com/v1/analyticsReportInstances/{instance_id}/segments' r = requests.get(URL_SEGMENTS, headers=HEAD) segments_response = r.json() segments = {} for segment in segments_response.get('data',[]): segment_id = segment['id'] url = segment['attributes']['url'] checksum = segment['attributes']['checksum'] segments[segment_id] = { 'url': url, 'checksum':checksum } return segmentsget_segments_by_instance 函式用於訪問與特定例項相關的每個片段的下載網址。該函式利用 instance_id 構建 API 網址並傳送請求,以檢索這些片段。隨後,它會遍歷響應,提取每個片段的 segment_id、URL 和校驗和,並將它們儲存在一個字典(segments)中。這一過程使得可以直接訪問每個片段的詳細且經過驗證的資料,隨時準備進行下載和最終處理。下載 - 提取 - 驗證 功能
def download_extract_validate(url,checksum,temp_file_name): response = requests.get(url) with open(temp_file_name,'wb') as file: file.write(response.content) md5 = hashlib.md5() with open(temp_file_name,'rb') as f: while chunk := f.read(8192): md5.update(chunk) if md5.hexdigest() != checksum: raise ValueError(f"Checksum mismatch!") else: print("Checksum validated.") extracted_file_path = temp_file_name[:-3] with gzip.open(temp_file_name, 'rb') as f_in: with open(extracted_file_path, 'wb') as f_out: f_out.write(f_in.read()) return extracted_file_pathdownload_extract_validate 函式負責下載報告、提取檔案並使用先前收集的校驗和來驗證其完整性。最初,它會請求報告的 URL 並將內容儲存到臨時檔案中。接著,函式開始進行驗證過程,透過建立下載內容的 MD5 雜湊值並與預期的校驗和進行比較。如果發現不一致,函式將引發錯誤以指示驗證失敗;否則,它將確認該檔案已成功透過驗證。
在驗證之後,該函式將提取壓縮內容,移除檔案路徑中的 .gz 字尾,並將其解壓縮到一個新檔案中。這個經過驗證且格式正確的提取檔案將作為 extracted_file_path 返回,準備進行後續處理步驟。此函式確保傳輸資料的完整性並高效地為 BigQuery 載入管道準備檔案。這是用於將資料載入到 BigQuery 的函式。
def send_to_gbq(extracted_file_path,table_id,project_id): df = pd.read_csv(extracted_file_path, delimiter='\t') df.columns = ['created_at' if col == df.columns[0] else col for col in df.columns] if df.empty: print(f"No data found in {extracted_file_path}") return False credentials, _ = default() to_gbq(df, table_id, project_id=project_id, if_exists='replace', credentials=credentials, api_method="load_csv") return True讀取與處理檔案:使用 pd.read_csv 讀取檔案,並以製表符(\t)作為分隔符,將其轉換為 DataFrame(df)。接著,如果原始列名為 ′Date′,則將第一列重新命名為 created_at,以確保通用的日期名稱在未來進行 SQL 操作時不會產生衝突,此舉遵循了所涉及資料倉庫的最佳實踐。資料驗證:在傳送資料之前,該函式會檢查 DataFrame 是否包含任何資料。如果它是空的(df.empty),該函式將列印一條訊息並結束過程,返回 False,以防止空表格被載入至 BigQuery。
將資料載入 BigQuery:透過使用預設的服務憑證(由 default() 獲取),該函式認證執行 Google Cloud Function 的服務帳戶,這也是我們已經授予 BigQuery 存取許可權的同一個帳戶。接著,該函式使用 to_gbq 將 DataFrame 傳送到指定的 BigQuery 表格(table_id)內的專案(project_id)。如果表格已存在,則會被替換(if_exists=′replace′),這樣可以在不重複資料的情況下更新資料。由於 App Store 定期進行更新,因此確保了資料始終保持最新狀態。
成功確認:該函式返回 True,這表示過程已成功完成,允許在資料載入後管道的後續階段繼續進行。此函式確保資料格式正確,以防止常見的相容性和操作問題,並將處理後的資料集中在 BigQuery 中,以便於未來更輕鬆地查詢和分析。這是一個從報告列表執行完整管道的函式。
def complete_process(report_ids,type): # First loop, collecting instances ID per report IDs for report_name, report_id in report_ids.items(): r = requests.get(f'https://api.appstoreconnect.apple.com/v1/analyticsReports/{report_id}/instances', headers=HEAD) instances_response = r.json() instances_ids = get_instances_ids_by_report(instances_response) # Second loop, collecting segment_lists by instances IDs for instance_id, instance_data in instances_ids.items(): r = requests.get(f'https://api.appstoreconnect.apple.com/v1/analyticsReportInstances/{instance_id}/segments',headers=HEAD) segments_response = r.json() segments_list = get_segments_by_instance(instance_id) # Third loop, collecting download URLs and downloading, extracting and validating each part for segment_id, segment_data in segments_list.items(): print(f"TYPE: {type}, Report Name: {report_name}, Report Id: {report_id}, Instance ID: {instance_id}, Instance Granularity: {instance_data['granularity']}," f"Instance Data: {instance_data['processingDate']}, Segment URL: {segment_id}, Segment URL: {segment_data['url']}, Segment Checksum: {segment_data['checksum']}") # Downloading, extracting and validating extracted_file_path = download_extract_validate(segment_data['url'], segment_data['checksum'], temp_file_name) print(f"Downloaded and extracted file to: {extracted_file_path}") # Sending to GBQ clean_report_name = report_name.replace(" ", "") # Adjusts to guarantee the report name is prepared clean_processing_date = instance_data['processingDate'].replace("-", "") # to be automatically grouped in BigQuery (oriented to "_", underlines) table_id = f"{dataset}.{type}_{clean_report_name}_{instance_data['granularity']}_{clean_processing_date}" if send_to_gbq(extracted_file_path, table_id, project_id): print(f"File {report_name}_{instance_data['granularity']}_{instance_data['processingDate']} successfully uploaded to BigQuery.\n") else: print(f"Report {report_name}_{instance_data['granularity']}_{instance_data['processingDate']} not uploaded.\n")最佳化大型資料處理流程:函式拆解、Serverless 架構與 AI 異常偵測
函式 `complete_process` 執行一整個從報告列表中提取的處理流程。它收集報告的 ID,然後針對每個報告檢索相關例項和區段的 ID。接著,對於每個區段,此函式會進行檔案的下載、驗證以及使用校驗碼進行資料擷取,隨後將擷取到的資料傳送至 BigQuery。在 BigQuery 中,表格名稱會根據報告名稱、例項粒度及處理日期動態生成。如果檔案成功上傳,函式將印出確認訊息;否則則會報告錯誤。這整個過程將針對所提供列表中的每一份報告重複執行。為了提升系統的彈性與擴充套件性,我們可以考慮在 Serverless 平台(如 Google Cloud Functions 或 AWS Lambda)上架構 `complete_process` 函式。這樣做不僅能有效降低運營成本,同時也提高處理速度,使得系統能夠自動根據需求伸縮。在面對大量報告時,傳統單體應用程式容易遇到瓶頸,而 Serverless 架構則能解決此問題。我們可以將 `complete_process` 函式拆分成更小、更獨立的 Serverless 函式,例如:`collect_report_ids`、`retrieve_instance_segment_ids`、`process_segment` 及 `upload_to_bigquery` 等,每個函式專注於單一任務,以便於維護和除錯。可以利用 Serverless 平台提供的監控和日誌功能來精確追蹤每個函式的執行時間與資源消耗,以進一步最佳化效能。
在資料驗證方面,目前 `complete_process` 函式已描述檔案校驗碼(checksum)的驗證,但這僅是初步措施。隨著資料量增加及其複雜度加大,更強大的驗證機制變得至關重要。我們可以結合 AI 驅動的異常偵測模型,如使用機器學習演演算法分析資料統計特性,自動識別潛在錯誤或異常值。一旦偵測到異常,系統可自動觸發修復機制,例如填補缺失值或去除異常值。引入 AutoML 等工具還能降低 AI 模型訓練及部署門檻,使得我們可以根據具體業務需求定製化異常檢測模型。
綜合以上最佳化方向,不僅可提升資料處理可靠性,也有助於增強整體系統健壯性並減少人工幹預,實現自動化錯誤修復。因此,在設計此類流程時,我們應該注重如何透過新技術提升效能與效率,以符合未來發展趨勢。
BigQuery 資料表命名規範與最佳實務
BigQuery 中資料表的完整路徑將遵循以下模式,如下程式碼所示:<dataset>.<type>_<report_name>_<granularity>_<processing_date>。其中,<dataset>: 代表在 BigQuery 中儲存資料表的資料集名稱;<type>: 表示報告的型別,目前有兩種選擇:′ONGOING′ 和 ′SNAPSHOT′;<report_name>: 報告名稱,並去除空格;<granularity>: 例項的粒度,可選擇 ′DAILY′、′WEEKLY′ 或 ′MONTHLY′;<processing_date>: 例項的處理日期,以無連字元格式顯示(例如:′20241010′)。
在接收 POST 請求並呼叫主函式時,開發者應該考慮到系統的可擴充套件性和容錯性。在設計這個功能時,可以納入一些最佳化策略,例如:
1. **加入版本號**: 在 <processing_date> 後附加版本號(如 `20241010_v1`),以便於進行版本管理及回滾操作。
2. **匯入命名規範驗證**: 在 POST 請求處理函式中加入命名規範檢查,提前偵測並回報錯誤,以避免資料寫入失敗。
3. **錯誤日誌與監控**: 實施完善的錯誤日誌及監控機制,用以追蹤資料表命名錯誤及其他異常情況,例如利用 BigQuery 的 Audit Logs 或 Cloud Logging。
在日期格式方面,可以考慮使用更健壯的日期處理函式庫,同時引入容錯機制,比如將日期轉換出現錯誤視為例外來處理,記錄相應訊息,而不是直接終止程式執行。這樣一來,不僅能提升系統穩定性,也能幫助專家迅速定位和解決問題。
除了上述命名規範之外,更需關注資料治理最佳實務。例如,可以考量如何將此命名規範與現有資料治理流程整合,以及確保所有資料表命名符合公司的內部標準。透過與公司內部資料目錄(如 Data Catalog)的整合,可以自動化註冊和搜尋過程,提高資料發現性和可管理性。同時結合 BigQuery 的生命週期管理功能,自動化管理各項資料表生命週期,有效減少人工幹預及潛在錯誤風險。基於清晰的路徑命名規則,也可以設計精細化許可權控制策略,以強化資料安全性。這些策略不僅可以確保資料符合法規要求,也能提升公司內部政策對於資料治理效率和有效性的支援。
@functions_framework.http def start(request): threading.Thread(target=get_data).start() return {"status": "Started processing"}, 200這個啟動功能是一個雲端函式,當接收到一個 HTTP POST 請求時,它會非同步地啟動資料處理,使用執行緒來進行。透過使用 @functions_framework.http 裝飾器,它建立了一個獨立的執行緒來執行 get_data 函式,使得處理可以在後台持續進行,而不會阻塞對排程器的回應。這確保了排程器能夠準時收到狀態 200 的回應,而不會在流程中引發錯誤,同時也表明資料處理已經開始進行。
主函式負責協調整個執行過程
def get_data(): # Global variables global HEAD, request_id_ongoing_report, request_id_one_time_snapshot, params_limit, temp_file_name, project_id, dataset # Variables that identify the Google Cloud Storage bucket BUCKET_NAME = 'XXXXXXXXXX' # Name of the GCS bucket where the auth key is stored FILE_NAME = 'XXXXXXXXXX.p8' # Name of the private key file stored in GCS TEMP_KEY_PATH = f'/tmp/{FILE_NAME}' # Temporary local path to store the key # Variables that identify the App Store Acount KEY_ID = "XXXXXXXXXX" # Recurring access key ID ISSUER_ID = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" # Team ID for App Store Connect EXPIRATION_TIME = int(round(time.time() + (20.0 * 60.0))) # Expiration timestamp (20 minutes from now) # Download the key from Google Cloud Storage download_key_from_gcs(BUCKET_NAME, FILE_NAME, TEMP_KEY_PATH) # Open the downloaded private key with open(TEMP_KEY_PATH, 'r') as f: PRIVATE_KEY = f.read() # Authorization header with JWT (JSON Web Token) header = { "alg": "ES256", # Algorithm used for JWT "kid": KEY_ID, # Key ID used in the JWT "typ": "JWT" # Type of the token } payload = { "iss": ISSUER_ID, # Issuer ID (team ID) "iat": round(time.time()), # Issued at time (current timestamp) "exp": EXPIRATION_TIME, # Expiration time of the token "aud": "appstoreconnect-v1" # Audience of the token (App Store Connect API) } # Generate the JWT token using the private key token = jwt.encode(header, payload, PRIVATE_KEY) JWT = 'Bearer ' + token.decode() # Format the token as a Bearer token for authorization HEAD = {'Authorization': JWT} # Authorization header ready for use # Report IDs for ongoing and one-time snapshot reports request_id_ongoing_report = 'XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX' # Relatório ONGOING GERADO DE UM A DOIS DIAS ANTES DO ONE-TIME-SNAPSHOT request_id_one_time_snapshot = 'XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX' # ONE-TIME-SNAPSHOT GERADO NO DIA 03/07/2024 - 18:06 # Base URLs for fetching reports using the report IDs URL_ONE_TIME_REPORT = f'https://api.appstoreconnect.apple.com/v1/analyticsReportRequests/{request_id_one_time_snapshot}/reports' URL_ONGOING_REPORTS = f'https://api.appstoreconnect.apple.com/v1/analyticsReportRequests/{request_id_ongoing_report}/reports' # List of reports relevant to our business needs at the time reports = [ # Essential reports "App Store Discovery and Engagement Detailed", "App Downloads Detailed", "App Install Performance", "App Store Installation and Deletion Detailed", # Additional reports "App Disk Space Usage", "Location Sessions", "App Crashes Expanded" ] # Temporary file name to store downloaded CSV data temp_file_name = "temp_download.csv.gz" # Fixed parameters defining the destination for the data in BigQuery project_id = "XXXXXXXXXXXXXXX" dataset = "AppStore" params_limit = {'limit': 200} # Set limit for the number of records to fetch in each request # Fetching the one-time snapshot report data r = requests.get(URL_ONE_TIME_REPORT, headers=HEAD, params=params_limit) report_response = r.json() report_ids_one_time_snapshot = get_report_ids_by_name(report_response,reports) print(f'ONE TIME SNAPSHOT REPORTS: \n {report_ids_one_time_snapshot}') # Fetching ongoing report data r = requests.get(URL_ONGOING_REPORTS, headers=HEAD, params=params_limit) report_response = r.json() report_ids_ongoing = get_report_ids_by_name(report_response,reports) print(f'ONGOING REPORTS: \n {report_ids_ongoing} \n\n\n') print("Starting to colect the ONE_TIME_SNAPSHOT data:") complete_process(report_ids_one_time_snapshot,'SNAPSHOT') print("Starting to colect the ONGOING data:") complete_process(report_ids_ongoing,'ONGOING') return "Data collection completed successfully.", 200提升App Store Connect資料擷取效率與品質的get_data函式最佳化策略
`get_data` 函式是整個資料管道的核心,下面將依執行順序概述其步驟:1. **識別 Bucket 和 App Store**:該函式首先配置關鍵變數,例如儲存身份驗證金鑰的 bucket 名稱。還會宣告用於識別帳戶和應用程式的變數,以便從中收集資料。
2. **透過 JWT 進行身份驗證**:函式從 bucket 中下載身份驗證金鑰,並與已配置的變數結合。根據這些資訊構建 JWT(JSON Web Token)標頭,此標頭用於授權請求至 App Store Connect API。
3. **識別相關報告以擷取**:該函式定義了兩個關鍵點以進行資料收集:需要擷取的報告 ID,根據先前步驟提供的資訊將其分為持續性(ONGOING)和一次性快照(ONE_TIME_SNAPSHOT)報告。還建立了一份相關報告清單,依名稱進行篩選。這一清單是基於可用報告完整列表的分析而建立,可以根據業務需求輕鬆調整。如果您想要分析完整列表,可以檢視對非分析 URL 的請求回應,如下所示:
- [一次性快照報告](https://api.appstoreconnect.apple.com/v1/analyticsReportRequests/{request_id_one_time_snapshot}/reports)
- [持續性報告](https://api.appstoreconnect.apple.com/v1/analyticsReportRequests/{request_id_ongoing_report}/reports)
4. **識別接收資料的 GCP 專案和資料集**:此配置僅使用之前收集到的兩個變數來完成,即 project_id 和在我們資料倉庫中建立的 dataset。
5. **API 請求及資料收集**:接下來,該函式向 API 發出請求,以收集可用報告的 ID。基於這些 ID,呼叫 `complete_process` 函式,它負責協調下載、驗證、處理以及將資料傳送至 BigQuery 的各個階段。`complete_process` 函式會針對 ONE_TIME_SNAPSHOT 資料和 ONGOING 資料分開執行。`get_data` 函式結束了資料收集和提交過程,返回一條成功訊息,以指示資料已成功收集並傳送至 BigQuery。
在設計高效且穩健的 `get_data` 函式時,也需要考慮到以下幾點最佳化策略:
- **Rate Limiting 與重試策略**:內建智慧型重試機制以偵測並處理 App Store Connect API 的速率限制問題,例如使用指數退避演演算法 (exponential backoff) 以及適當錯誤碼處理(如 429 Too Many Requests)。
- **批次請求 (Bulk Requests)**:善加利用 App Store Connect API 所支援的一次請求獲取多份報告功能,以減少 API 呼叫次數,提高效率。
- **非同步處理 (Asynchronous Processing)**:對大量資料採取非同步模式,例如使用 asyncio(Python),可以顯著縮短整體執行時間,同時最大化並行度。
- **錯誤日誌與監控**:記錄所有 API 請求、回應及任何錯誤訊息以方便追蹤與除錯,並可整合監控系統,如 Prometheus 和 Grafana,即時追蹤資料擷取進度及狀態。
在確保有效率地將資料匯入 BigQuery 時,也需注意以下幾項細節:
- **嚴格的資料驗證步驟**:檢查所取得之 APP STORE CONNECT 資料是否具備完整性、一致性及正確性,包括型別驗證和值範圍等檢查程式。
- **必要之轉換**: 確保能夠符合 BigQuery 資料模型要求,包括格式轉換及正規化等步驟。
- **最佳化 Schema 設計**: 根據 APP STORE CONNECT 報表結構設計最最佳化之 BigQuery Schema ,提高查詢效能與降低儲存成本。
透過以上方法,我們不僅可以提升 `get_data` 功能效率,更能保障最終輸出的準確度及可靠性,使得在大規模運營環境中的決策支援更加有力。
在資料收集後,這些資料會被整理到 Google BigQuery 的不同表格中。為了使這一分組過程能夠自動化,維持一致的命名規則對於所載入的檔案至關重要,確保名稱之間僅存在小幅度變化。我們透過從預定義的變數和程式碼中的模式生成每個表格的命名來實現這一點。這使得 BigQuery 能夠正確地分組資料,並促進使用萬用字元執行查詢,從而分析多個表格,而無需單獨指定每個表格。以下是資料排列的一個示例:
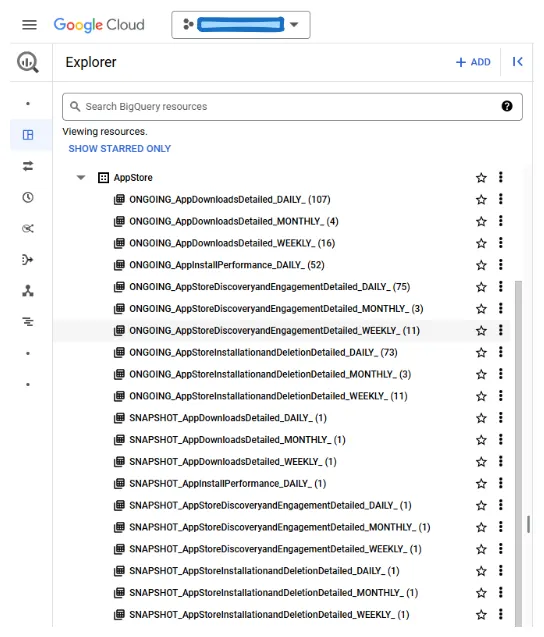
文件:使用萬用字元表查詢多個表格
雖然我沒有為每一個步驟實施健全的日誌記錄過程,但 Google Cloud Function 仍然會為每次列印生成日誌。這是一種更簡單的解決方案,在實施的情況下,能夠建立足夠完整的痕跡,以識別潛在問題以及系統中需要注意的部分。以下是從使用的列印函式所產生的日誌條目示例:
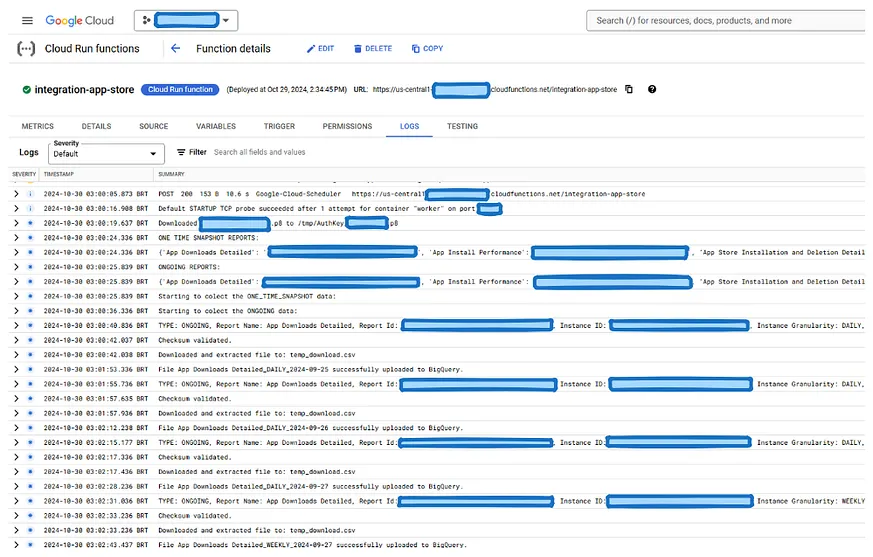
最佳化 BigQuery 資料管道:從記憶體最佳化到 Serverless 架構
在上面的圖片中,我們可以觀察到每個流程步驟,從排程器發出的 POST 請求開始,每個檔案被提取、驗證並載入到 BigQuery,直到處理過的資料進入生產環境。至此,我們完成了端對端功能的實現。追求持續改進對於確保更高效且可持續的解決方案至關重要。以下是一些建議的增強措施:**資料統一:** 實施一種結構以實現資料的統一,從而減少對萬用字元搜尋的依賴。這將提高效能並減少在 BigQuery 中查詢的複雜性。我甚至建立了一段程式碼來執行此過程,我會將其新增到 GitHub 倉庫中,作為任何有興趣者的附加資源。它仍然需要強化最佳化,因為在 1 GiB 的機器上執行時消耗了太多記憶體,而根據我的看法,其執行時間約需 15 分鐘。
**記憶體最佳化:** 我建議考慮我們必須為管道分配 2 GiB 記憶體之情況,注意到我們所處理的是小資料量。一個單獨 App Store 應用程式的資料具有更具分析性的細粒度和每日時間劃分,因此不會有超過 5,000 行的表格。因此,我相信在 complete_process 函式內部應該有釋放記憶體的空間。
**桶中的檔案評估與驗證:** 正如我在關於整合 Play Store API 資料的文章中提到,此示例也將受益於使用 replace 函式來最佳化相似檔案傳送的方法。在桶中評估和驗證檔案,可以確保只有新表格和有變更的表格提交給資料管道。此方法需要處理的不僅是不同檔名,也包括已載入檔案的回溯更新。有了這樣的方法,就能消除使用 replace 方法所需,提高程式碼效率並提升整體效能。
在面對記憶體瓶頸(1 GiB 機器執行資料統一程式耗費大量記憶體)及明顯過剩預算(2 GiB)的問題時,我們可以匯入更先進的雲端資源管理策略。傳統批次處理方式容易造成資源浪費,而若轉向 Serverless 架構(例如 AWS Lambda、Google Cloud Functions 和 Azure Functions),則能根據需求動態調整計算資源,有效降低成本與提升效率。同時結合自動規模調整功能 (Autoscaling),系統可根據輸入數量自動調整執行例項,保障穩定性與處理速度,更有效避免閒置及不足問題。更輕量級框架如 Apache Spark 的輕量版或 Dask 等,也適合小型至中型資料集,可更有效利用記憶體。
針對檔案驗證與更新問題,也可透過完善版本控制策略來解決。目前使用 `replace` 函式更新檔案的方法效率較低且易出錯,因此建議匯入支援版本控制系統(如 Git LFS)儲存資料檔案,再搭配 BigQuery 的版本管理功能。例如,以時間戳或版本號追蹤更新,每次資料更新都提交新的檔案至 Git LFS 並附上版本資訊,使得 BigQuery 根據這些資訊決定是否覆蓋舊資料或進行增量更新,此舉不僅避免重複匯入相同資料,同時也提升了效率及降低錯誤風險。可運用變化資料捕捉技術 (Change Data Capture, CDC),只匯入變更後的新資料以進一步最佳化流程。
這些方案不僅解決了檔案更新問題,同時提升了資料跟蹤能力與恢復性。在 Git LFS 支援下,我們能夠輕鬆追蹤變化並回滾版本,提高管理可靠性和安全性。而所有這些改善措施均需考慮當前系統架構和監控機制,相應工具如 Apache Airflow 可助力有效排程與管理任務。
我感謝所有閱讀到這裡的人,這是一段漫長的旅程!如果有任何問題或改進建議,我隨時歡迎。
參考來源
 全部
全部 生活休閒
生活休閒
相關討論